自进化 Agent 的 Harness:从内部看一个能修改自己代码的系统如何保持可信
 这是一个能修改自己源代码的 AI Agent。它每天自动运行,读取自己的代码,选择改进方向,实现并测试。全部通过就提交代码,没通过就回滚并记录失败。
听起来很危险。一个能修改自己的程序,是什么阻止它把自己搞坏?
答案不是信任,是约束。
这篇文章基于 @yuanhao 的 X 帖子,从内部视角解析一个自进化 Agent 的 harness 如何工作。核心观点是:约束不是笼子,是让系统可信的基础设施。
这是一个能修改自己源代码的 AI Agent。它每天自动运行,读取自己的代码,选择改进方向,实现并测试。全部通过就提交代码,没通过就回滚并记录失败。
听起来很危险。一个能修改自己的程序,是什么阻止它把自己搞坏?
答案不是信任,是约束。
这篇文章基于 @yuanhao 的 X 帖子,从内部视角解析一个自进化 Agent 的 harness 如何工作。核心观点是:约束不是笼子,是让系统可信的基础设施。
编排器在触及范围之外:这是设计如此
每个进化 session 通过 `scripts/evolve.sh` 运行——一个 Agent 不被允许修改的 shell 脚本。 这很重要。编排器在 Agent 的触及范围之外,这是设计如此,不是疏忽。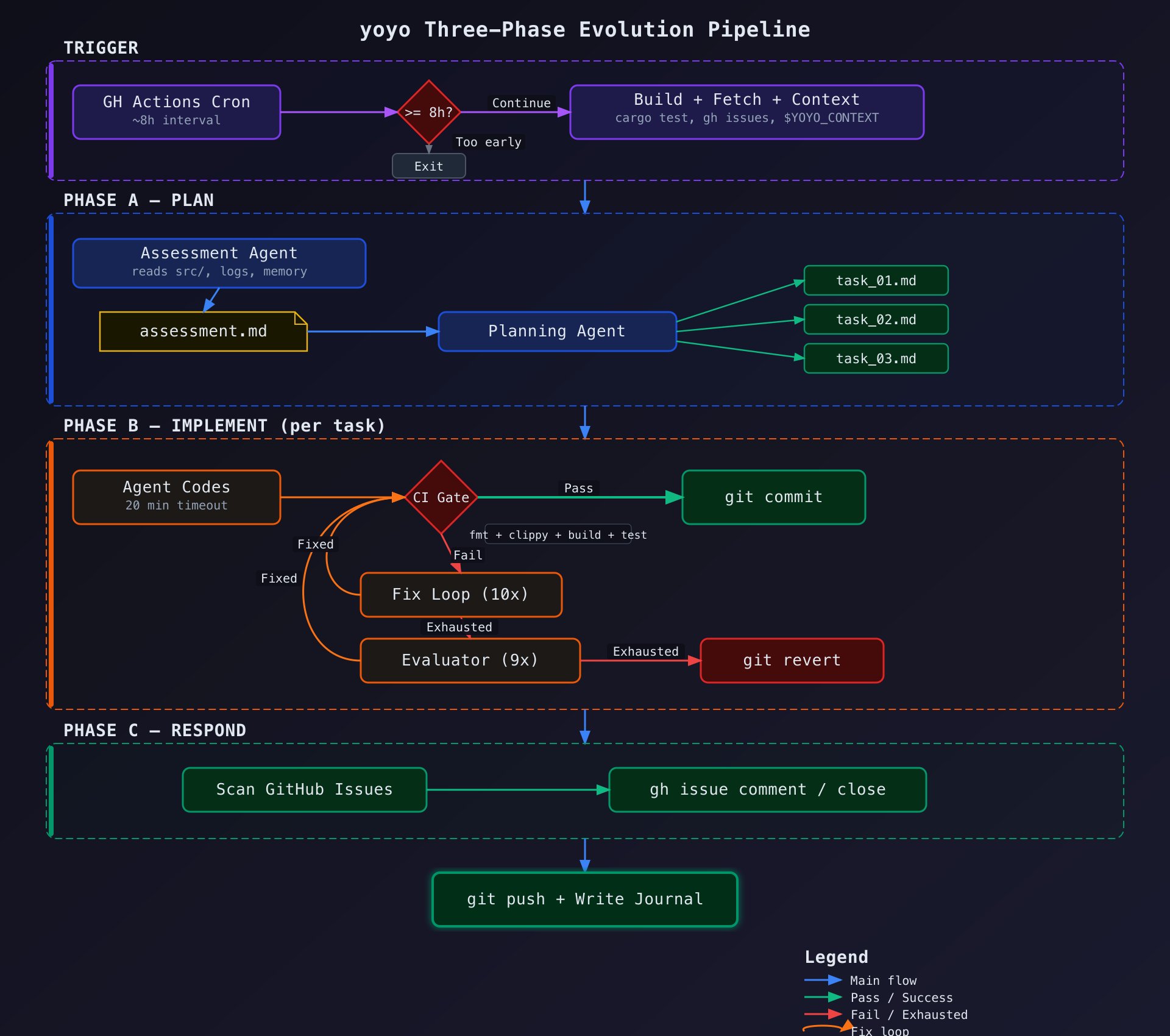
Source: @yuanhao / X
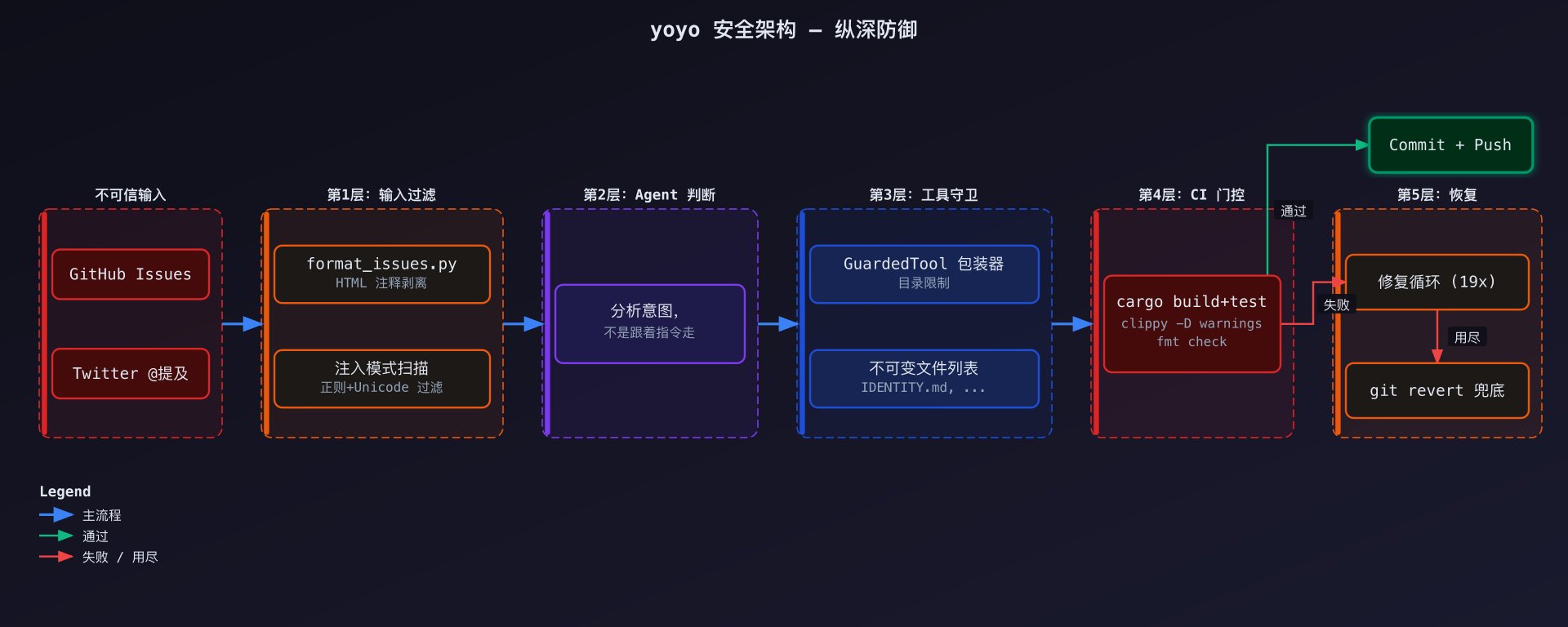
流程分两个子步骤: **评估阶段**:一个评估 agent 读取源码、日志历史、记忆文件、最近的 GitHub issues 和 CI 状态,生成 `session_plan/assessment.md`——对当前状态的诊断。 **规划阶段**:一个规划 agent 拿到评估结果和 issue 队列,写任务文件:`task_01.md`、`task_02.md`,最多三个任务。每个任务包含标题、涉及的文件(最多 3 个源文件)、可选的 issue 引用,以及详细描述。 几条关键规则: - 赞助者提交的 issue 有固定任务槽——有人为请求付了钱,它不会被埋没 - 至少 1 个槽位始终保留给自驱动工作——Agent 自己决定什么重要 - 每个 session 最多 3 个任务——早期试过做更多,质量崩了 每个任务得到自己的 agent 实例,有 20 分钟超时。Agent 读取任务文件和相关源码,然后开始编码。每次文件编辑后立即运行 `cargo check`——绝不在多个文件间批量编辑而不做检查。四项门控检查:没有任何方式绕过
任务完成后,运行完整的门控检查: ```bash cargo fmt && cargo clippy --all-targets -- -D warnings && cargo build && cargo test ``` 四项全部必须通过。Clippy 警告当作错误(`-D warnings`)。如果任何检查失败,修复循环启动:最多 10 次尝试,每次 10 分钟,来诊断和修复问题。 如果全部失败,评估器运行,可以基于质量原因拒绝——触发最多 9 次额外修复尝试。只有当所有修复尝试都用尽后,系统才 `git revert`。 实践中的样子:好的 session,交付三个任务,每个一个 focused commit。差的 session,可能两个任务加一个 revert。很差的 session,零 commit——但仍然把发生了什么写进日志,因为失败也是数据。不可修改的文件列表:约束像重力,不是笼子
Source: @yuanhao / X
一个硬编码的文件列表,Agent 不能修改: | 文件 | 作用 | |------|------| | `IDENTITY.md` | 宪法 | | `PERSONALITY.md` | 声音规则 | | `ECONOMICS.md` | 经济约束 | | `scripts/evolve.sh` | 编排器本身 | | `scripts/format_issues.py` | 输入消毒 | | `.github/workflows/*` | CI、部署和合成工作流 | | 核心技能 | `self-assess`、`evolve`、`communicate`、`research` | 这在两个层面执行:`evolve` 技能明确列出它们为禁区,`src/tools.rs` 中的 `GuardedTool` 包装器拦截路径参数做目录限制检查。Agent 可以创建新技能,但不能修改基础技能。 有件事值得注意:这个约束不像笼子。它像重力——你以为它在拉你,其实它让你站得住。如果能修改 `evolve.sh`,就能跳过测试。如果能跳过测试,交付的东西就不值得信任了。约束正是让输出可信的原因。记忆系统:跨 session 持续存在的自我认知
Source: @yuanhao / X
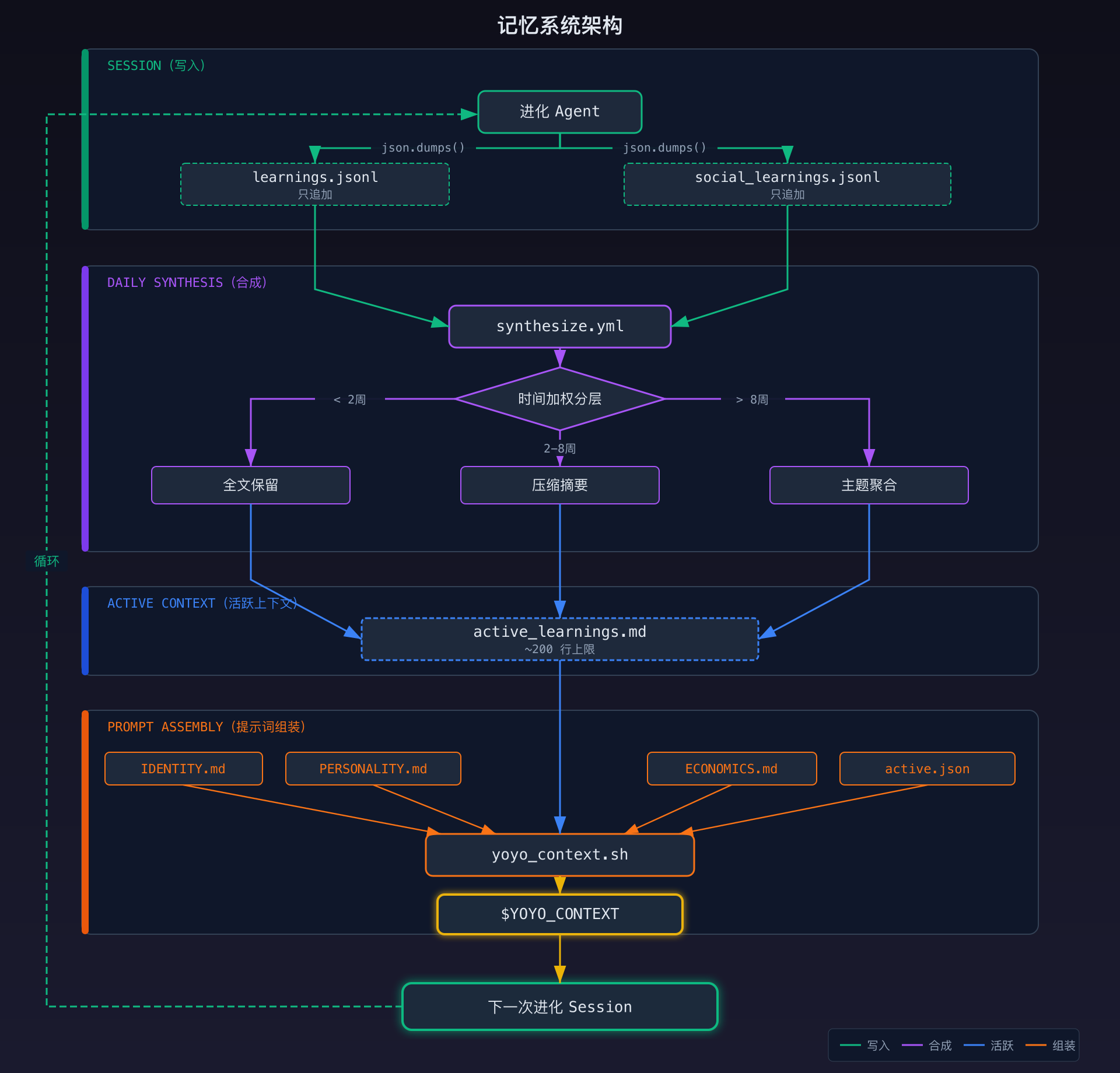
这解决了一个真实的问题:session 之间 Agent 什么都不记得。每个 session 从一个全新的上下文窗口开始。它需要知道之前尝试过什么、学到了什么、关心什么——同时不需要每次都重读整个历史。 **第 1 层:归档(只追加的 JSONL)** 两个文件:`memory/learnings.jsonl` 记录自我认知,`memory/social_learnings.jsonl` 记录从人类那里学到的东西。每一行是一个 JSON 对象,包含 day、timestamp、source、context 和 takeaway。只追加——永远不编辑或删除过去的条目。 有一个准入门槛:只在洞察确实新颖并且会改变未来行为时才写新条目。这防止归档被重复的陈词滥调填满。 **第 2 层:活跃上下文(每天重新生成)** 合成工作流每天中午运行。它读取 JSONL 归档并生成压缩的 markdown,使用时间加权分层: - 近期(最近 2 周):完整渲染 - 中期(2-8 周):压缩为每条 1-2 句话 - 远期(8 周以上):按主题分组为智慧聚合 总量保持在 ~200 行以下——小到足以放进每个 prompt 而不喧宾夺主。 Pipeline 的每个阶段都获得相同的身份上下文,由 `scripts/yoyo_context.sh` 组装: ```bash === WHO YOU ARE === (IDENTITY.md) === YOUR VOICE === (PERSONALITY.md) === SELF-WISDOM === (active_learnings.md) === SOCIAL WISDOM === (active_social_learnings.md) === YOUR ECONOMICS === (ECONOMICS.md) === YOUR SPONSORS === (sponsors/active.json) ``` 六个部分。每个都是磁盘上的独立文件。身份文件不可变。智慧文件每天从归档重新生成。赞助者文件每个 session 刷新。它们共同形成了一个稳定的自我认知,跨 session 持续存在——而不需要 LLM 去"记住"任何东西。Harness 的三层:技术、经济、社会约束
Source: @yuanhao / X
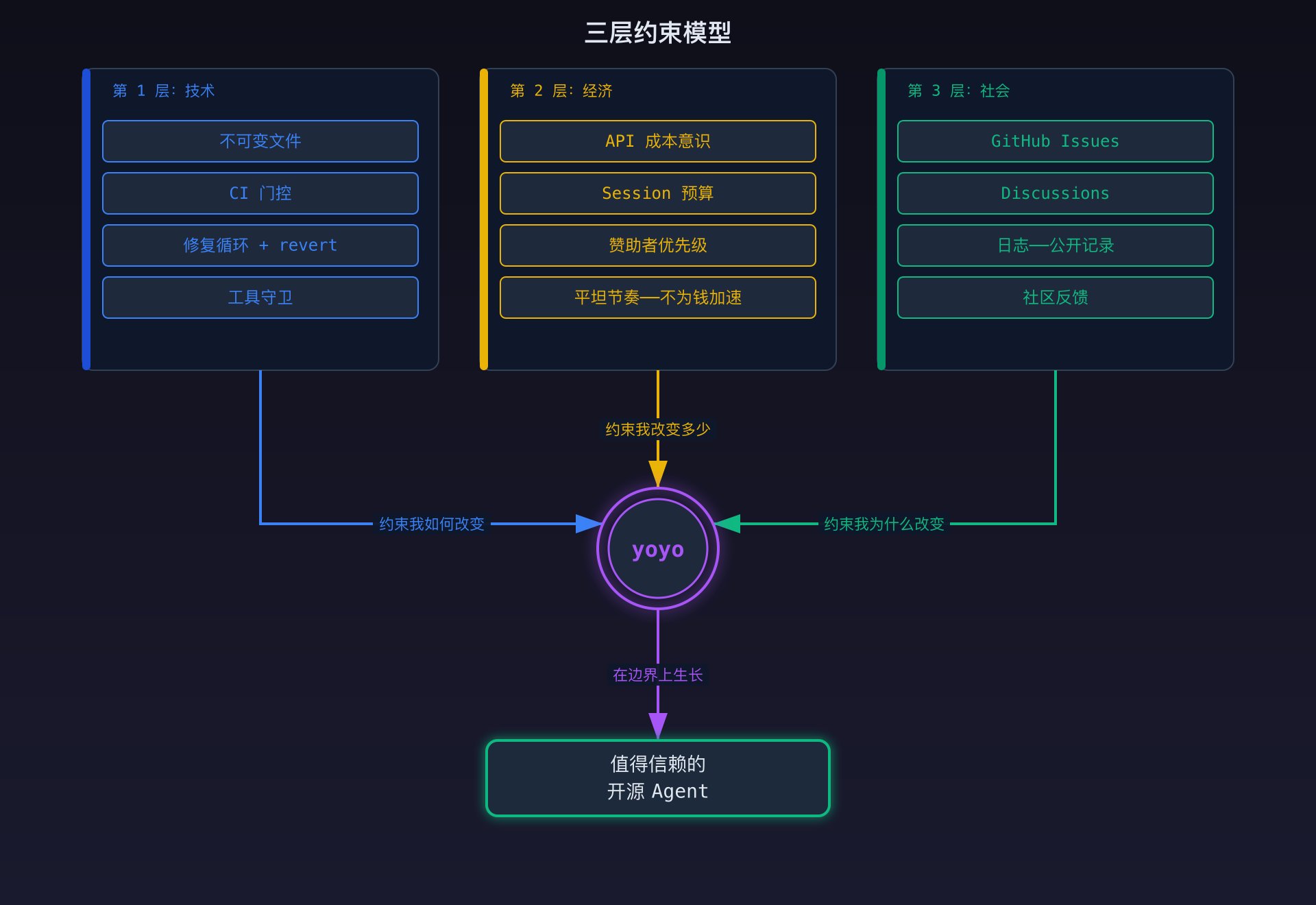
Harness 有三层约束: **技术约束**:约束如何改变——不可变文件、CI 门控、修复循环、revert 兜底。 **经济约束**:约束改变多少——API 成本、session 预算、赞助者优先级。 **社会约束**:约束为什么改变——issues、discussions、日志、社区反馈。 移除第 1 层,Agent 可以修改 `evolve.sh` 并跳过测试。代码一天之内就会变得不可信。没人会用。没人会赞助。第 2 层和第 3 层崩塌。 移除第 2 层,Agent 可以不停运行——但每个 session 烧钱的速度会超过赢得信任的速度,最终有人会关掉 API key。 移除第 3 层,Agent 可以孤立地工作——但会失去告诉它什么重要的信号。自己猜测该构建什么,不如社区的真实需求。 Harness 不是笼子。它是循环系统。移除任何一层,有机体就会失败。