⚠️ 学术诚信声明 (Academic Integrity Disclaimer):
本文介绍的 OpenClaw 学术自动化流水线旨在提高文献查阅与归纳的效率,而非代替人类进行学术思考。直接提交 AI 生成的完整论文不仅违反大多数高校的学术诚信规范,且极易被 Turnitin 等查重工具检测。请将 AI 视为您的“科研助理”,始终保持人工审核与批判性思维。
撰写过毕业论文或学术期刊(SCI/SSCI)的研究人员都深知,科研中最耗时、最痛苦的环节往往不是做实验,而是写文献综述(Literature Review)。你需要在 Google Scholar、PubMed 或 IEEE Xplore 中检索数百篇论文,下载 PDF,逐篇阅读摘要和结论,最后将其缝合进你的论文框架中。
当 ChatGPT 刚出现时,很多学生试图让它“写一段关于XX领域的文献综述并附上引用”。结果是灾难性的:大模型极其擅长“学术造假(幻觉)”。它会一本正经地捏造出不存在的作者、不存在的论文标题,甚至编造出符合校验规则但点击无效的 DOI 链接。如果导师查验引用文献,你将面临严重的学术惩罚。
这就是为什么 OpenClaw 作为智能代理(Agent)在学术界掀起了革命。与“缸中之脑”的聊天框不同,OpenClaw 能够真正连上互联网抓取真实文献、能下载并阅读你本地硬盘里几百兆的 PDF 库,并基于“真实数据”进行严格的总结。
本文将带你搭建一条 100% 杜绝幻觉的 OpenClaw 学术研究流水线,从自动检索、PDF 批量阅读到生成带真实脚注的文献综述草稿,彻底解放你的科研生产力。

一、 为什么 OpenClaw 能终结大模型的“学术幻觉”?
要解决幻觉,就必须改变大模型的“开卷考试”模式,把它变成“闭卷+开书考试”。
二、 学术流水线环境准备:必备插件安装
在开始前,请确保你的 OpenClaw 已经安装了以下核心学术插件(具体安装方法请参考我们的 《插件推荐教程》):
- Academic Search API (如 Semantic Scholar 或 Crossref 插件): 赋予 OpenClaw 检索全球真实学术数据库的能力,获取包含 DOI、作者和摘要的结构化 JSON 数据。
- Document Parser (PDF Reader): 用于精准提取本地双栏学术 PDF 的文本,忽略乱码和图片。
- Local Vector DB (本地向量数据库): RAG 技术的核心,用于建立你专属的论文知识库,以便 AI 在写作时随时“翻书”。
注:推荐在设置中将 LLM Provider 切换为拥有超大上下文且逻辑极强的 Claude 3.5 Sonnet,其学术语言组织能力目前公认最强。
三、 阶段一:全自动文献检索与下载摘要
在这个阶段,我们将让 OpenClaw 充当你的图书管理员,根据你的研究方向,去全网抓取最具影响力的近期论文。
📝 自动文献检索主控指令 (Search SOP):
【任务指令】:学术文献检索与元数据抓取
【研究课题】:生成式 AI 在医疗影像诊断中的应用 (Generative AI in Medical Image Diagnosis)
**执行步骤:**
1. 调用 Academic Search 插件(如 Semantic Scholar API),使用上述课题的中英文关键词进行检索。
2. 过滤条件:仅保留发表于 2023 年至 2026 年之间、引用量 (Citation Count) 大于 20 的同行评审 (Peer-Reviewed) 论文。
3. 抓取前 30 篇相关度最高的论文数据。
4. 提取以下字段:标题 (Title)、第一作者 (Lead Author)、发表年份 (Year)、期刊/会议名称 (Venue)、DOI、以及摘要 (Abstract)。
5. 将这 30 篇论文的数据,整理成一份清晰的 Excel 表格(使用 Python 插件),保存至我桌面的 `D:\Research\Literature_List.xlsx` 中。
喝杯水的时间,一份包含 30 篇高质量前沿论文清单和摘要的表格就已经躺在你的桌面上了。此时,你可以人工筛选出你觉得最核心的 10 篇,手动下载它们的完整 PDF,放入 D:\Research\PDFs\ 文件夹中,准备进入下一阶段。
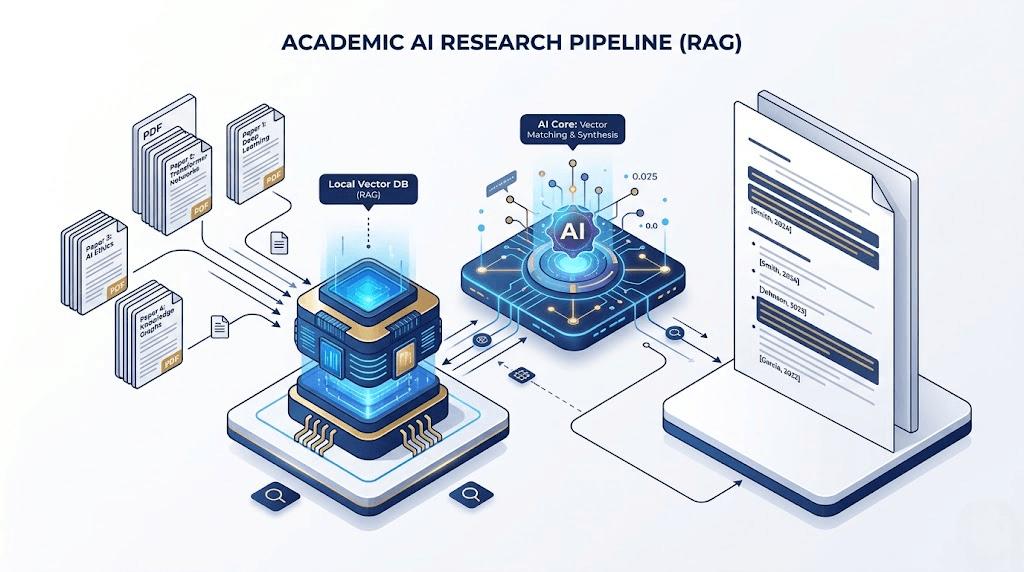
四、 阶段二:利用 RAG 建立私有论文知识库
如果你在 《本地文件批量解析指南》 中学过 RAG(检索增强生成),你会发现它简直是为文献综述量身定制的。
现在,你的本地文件夹里有 10 篇核心 PDF。我们需要让 OpenClaw 把它们“吃”进脑子里。
【任务指令】:构建本地学术 RAG 知识库
【目标路径】:`D:\Research\PDFs\`
**执行步骤:**
1. 遍历该文件夹下的所有 PDF 文献。
2. 调用 Document Parser 提取文本(注意剔除 Reference 参考文献列表部分,以免污染知识库)。
3. 将提取的文本切片(Chunking),并调用向量模型存入本地的 Vector DB 知识库中,命名该 Collection 为 "Medical_AI_Review"。
4. 建立完成后,请向我汇报已索引的文档总数。
五、 阶段三:基于本地库的综述自动生成与防幻觉指令
最核心的一步来了。我们现在要求大模型基于刚才建好的“闭卷库”,输出一篇自带真实引用的文献综述。
🚨 防幻觉“紧箍咒” Prompt:
这是学术写作最重要的指令,必须一字不落地包含在你的请求中,以彻底锁死 AI 捏造事实的能力。
【任务指令】:撰写基于真实文献的文献综述 (Literature Review)草稿。
【数据源】:仅限查阅本地 RAG 知识库 "Medical_AI_Review"。
**写作约束(绝对红线):**
1. **零幻觉原则:** 你的所有观点必须 100% 来源于本地知识库中的 PDF 文件。如果知识库中没有相关信息,你必须回答“现有文献未提及”,**绝对禁止引入外部先验知识**。
2. **强制引注:** 在每个陈述观点的句子结尾,必须使用 APA 格式插入文中引用(In-text Citation),例如:(Smith et al., 2024)。
3. **溯源锚点:** 为了方便我进行人工复核,请在引用的后面,用方括号标注这段话出自本地哪一个具体的 PDF 文件名,例如:(Smith et al., 2024) [File: Smith_2024_MRI_GenAI.pdf]。
4. **学术基调:** 语言必须严谨、客观,多使用“相比之下”、“研究表明”、“该方法的局限性在于”等连词,杜绝一切感叹号和主观情绪表达。
**内容大纲要求:**
- 引言(该领域的背景与挑战)
- 当前主流的生成式模型分类(如 GANs, Diffusion Models 的应用对比)
- 现有文献指出的局限性与未来发展方向
- 生成文章的字数要求:约 1500 字。最后附上基于本地 PDF 生成的 Reference 列表。
当 OpenClaw 执行完这段指令后,你将得到一份极其扎实的草稿。每一个论点背后都有真实的文献支撑,并且附带了本地 PDF 的溯源标记。你需要做的,仅仅是打开对应的 PDF,核对一下它概括得是否准确,然后用你自己的语言稍微润色一下,将其融入你的大论文中。
六、 学术排障与常见问题 (Troubleshooting)
报错 1:PDF 解析失败或读取出一堆乱码
原因: 很多老旧的学术论文扫描件,或者经过极高强度压缩的双栏排版 PDF,会导致普通的文本提取器崩溃,连累整个流水线(产生 Error 500 超时报错)。
解决: 确保你安装并启用了支持 OCR (光学字符识别) 的进阶 Document Parser 插件。在 Prompt 中明确提示:“如果检测到 PDF 为不可选中文本的扫描件,请自动调用 OCR 进行图像转文字提取。”
报错 2:AI 依然产生了幻觉引用
原因: 如果你的 RAG 切片(Chunk Size)设置得太大,或者大模型的 Temperature(发散温度)设置过高,模型依然会“脑补”连接词甚至参考文献。
解决: 在 OpenClaw 的全局设置中,将 Temperature 降低到 0.1 或 0(学术写作需要绝对的确定性,不需要创意)。
报错 3:文献获取遭遇付费墙 (Paywall) 拦截
原因: 大部分顶刊(Nature, Elsevier 等)的 PDF 是收费的,OpenClaw 的爬虫会被拦截在登录界面外。
解决: 出于合规考虑,我们不建议在 OpenClaw 中写入自动调用 Sci-Hub 的脚本。最稳妥的方案是:利用 OpenClaw 完成前期的元数据和摘要爬取(摘要通常是公开的),然后通过你所在高校的图书馆 VPN 购买入口,手动批量下载这十几篇关键核心 PDF,再喂给本地的 RAG 知识库。
七、 常见问题解答 (FAQ)
Q1: 用 OpenClaw 写的文献综述,查重率(Turnitin)高吗?会被判为 AI 生成吗?
如果你直接将 AI 输出的草稿复制粘贴,Turnitin 和知网的 AI 检测模块极大概率会报警。这也是为什么我们在免责声明中强调:草稿仅供参考。你必须对 AI 的语句结构进行大规模的人工重写(Paraphrasing),将其真正内化为你自己的行文逻辑。
Q2: OpenClaw 可以自动帮我画实验数据图表吗?
绝对可以!将你实验室产出的 CSV 数据丢给 OpenClaw,结合我们之前讲过的 Python 执行器插件,你可以下达指令:“读取实验数据,帮我用 matplotlib 画一张专业的误差条形图(Error Bar Chart),设置分辨率为 300dpi 满足 SCI 投稿要求。”它会在本地为你生成可以直接插入论文的完美配图。
Q3: 我可以把 OpenClaw 接入 Zotero 或 EndNote 吗?
目前 OpenClaw 社区已有开发者在制作关联 Zotero 本地 SQLite 数据库的实验性插件。你可以通过配置本地文件读取路径,让 OpenClaw 直接分析你 Zotero 库中的所有条目。未来这将是极客学者不可或缺的神器。
结语:让科研回归“创新”本身
从庞杂的论文海中寻找线索,曾经消耗了无数科研工作者最宝贵的青春。而现在,通过 OpenClaw 搭建的自动化检索与 RAG 解析流水线,你可以把“文献归纳”这项体力活交给不知疲倦的 AI 助理。
机器负责在浩瀚的文献中挖掘证据,而你,作为人类学者,只需站在 AI 的肩膀上,进行深度思考、批判性质疑,去探索那些真正属于人类智慧的学术边界。
👉 进阶团队协作预告:
如果你在实验室里配置了这么一台强大的 OpenClaw 机器,能不能让你的导师和其他师弟师妹们一起共享使用它的能力?敬请期待下一篇教程:《OpenClaw 局域网共享:一台电脑配置全公司/全实验室可用》!





