Key Takeaways
- Playwright MCP 和 Jumei.ai 配合,不是把所有动作都塞进浏览器,而是先分清浏览器层、移动端层和 Skills 编排层。
- 浏览器侧更适合网页后台、表单、管理页和结构化读取;移动端侧更适合 App 内动作、账号承接和云手机执行。
- Skills 的价值,不在替代执行环境,而在把 SOP、顺序、条件判断和结果回收串起来。
- 更稳的落地顺序通常是:先跑通浏览器最小任务,再补移动端任务,最后再把两边接成同一条流程。
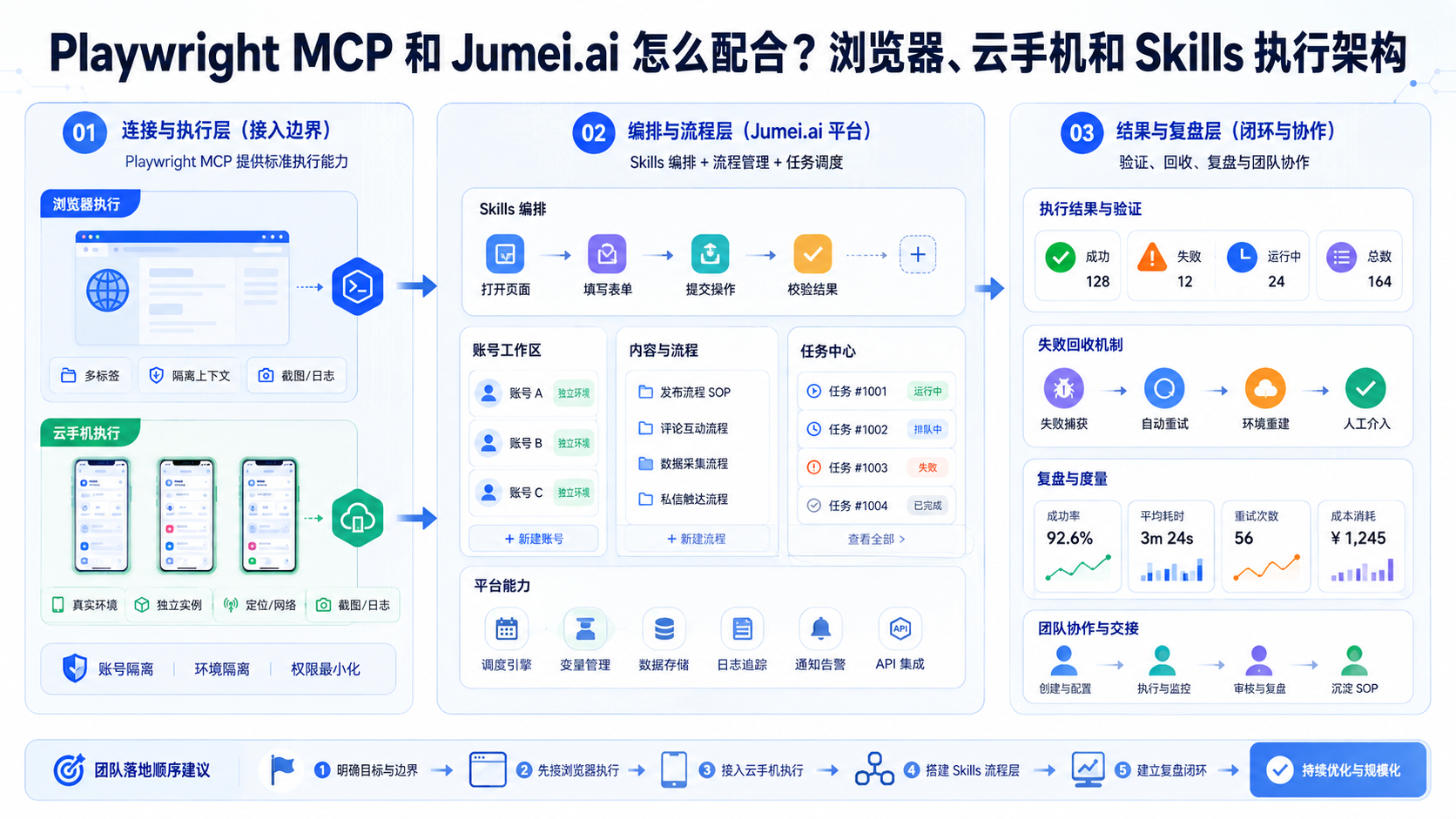
Playwright MCP 和 Jumei.ai 怎么配合,核心是把网页执行、移动端执行和 SOP 回收拆开。
- 网页后台、表单、管理页,先接 Playwright MCP。
- TikTok、WhatsApp、Instagram 这类 App 动作,补 云手机执行环境。
- 多人协作、失败回收、顺序判断,交给 自动化运营流程。
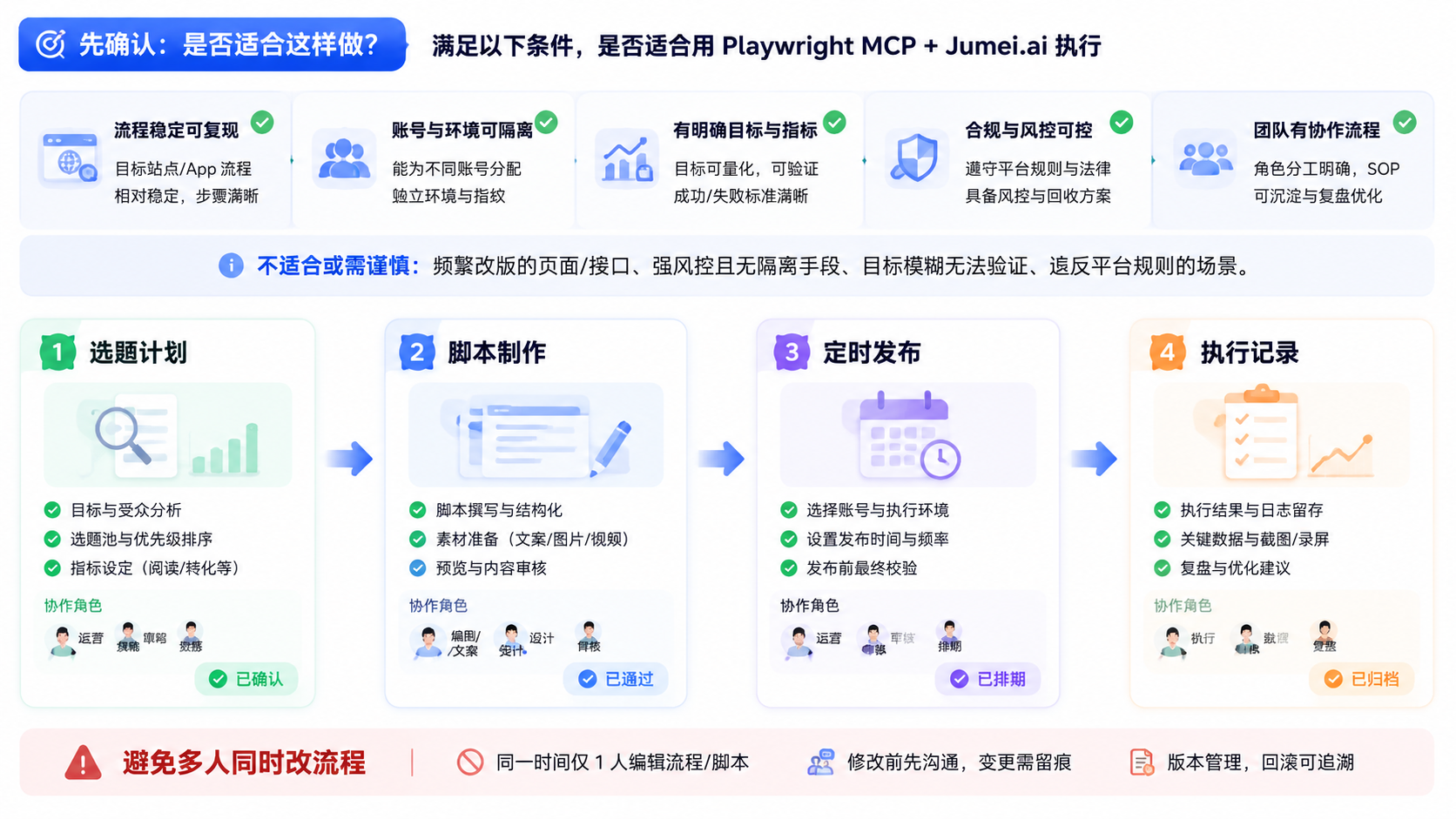
Playwright MCP 和 Jumei.ai 怎么配合前先确认是否适合这样做
Playwright MCP 和 Jumei.ai 怎么配合,更适合两类团队。
- 一类是网页任务和移动端任务并存的团队。
- 一类是已经有 SOP,需要把“谁执行、在哪执行、结果回到哪里”写清楚的团队。
如果你现在只有一个轻量网页动作,例如偶尔打开一个后台看标题,先单用 Playwright MCP 通常就够了。Playwright 官方文档把 MCP 定义为通过 Model Context Protocol 提供浏览器自动化能力,并强调结构化 accessibility snapshots 是核心交互方式。Playwright MCP
快速判断
- 只有网页任务:先接 Playwright MCP。
- 网页和 App 任务并存:再接 Jumei.ai。
- 还没定责任人和 SOP:先补流程,不要急着扩能力。
适合先接
- 网页任务和移动端任务同时存在
- 团队已有固定 SOP
- 需要区分不同执行环境
- 要记录失败原因和补救动作
先别急着接
- 只有单一网页动作
- 还没有任务分工
- 账号归属没有定清楚
- 团队暂时不做复盘
Playwright MCP 和 Jumei.ai 怎么配合前要准备什么
Playwright MCP 和 Jumei.ai 怎么配合前,至少要把三层前置条件对齐:执行环境、任务边界和结果回收。
- 执行环境决定网页动作在哪里跑。
- 任务边界决定哪些步骤属于浏览器、哪些属于云手机。
- 结果回收决定后面谁看状态、谁接异常。
从官方能力看,Playwright MCP 默认提供导航、快照、点击、输入、截图等核心浏览器能力;如果再打开 storage、testing、devtools 等 capability,才会出现更细的状态和调试能力。Playwright MCP capabilities
另外一个前置点是隔离。Playwright 官方把 browser contexts 定义为隔离的 clean-slate 环境,用来隔开 cookie、localStorage 和 sessionStorage。Playwright isolation
接入前检查清单
- 是否已经分清网页任务和 App 任务
- 是否已经定好账号归属
- 是否已经定好失败后谁接手
- 是否已经定好结果回收到哪里
| 层级 | 主要负责什么 | 不该混进去的内容 |
|---|---|---|
| Playwright MCP | 网页导航、快照、点击、输入、读取 | 移动端 App 动作 |
| 云手机 / 真机环境 | App 内执行、账号承接、移动端互动 | 网页后台表单自动化 |
| Skills / 流程层 | SOP 编排、顺序判断、结果回收 | 替代浏览器或替代设备本身 |
| 你当前的任务 | 先接哪一层 | 先别扩哪一层 |
|---|---|---|
| 网页后台录入和读取 | Playwright MCP | 云手机 |
| App 内登录和互动 | 云手机 / 真机 | 浏览器层硬扛 |
| SOP 串联和状态回收 | Skills / 流程层 | 只靠单点脚本 |
- 先定执行层,再定编排层
- 先定最小任务,再定扩展任务
- 先定结果回收,再定批量放大
Playwright MCP 和 Jumei.ai 怎么配合的核心步骤
更稳的接法通常只有四步,不建议一上来做大而全。
- 先用 Playwright MCP 跑通一个最小网页任务,例如打开后台、读取一个列表、点击一个按钮。
- 再把必须在 App 内完成的动作拆给云手机或真机环境,不要让浏览器层硬扛移动端任务。
- 把这两类动作写进 Skills,明确前后顺序、条件和失败后的下一步。
- 最后再把任务状态回收到 Jumei.ai 的流程视角里,方便后续复盘和交接。
这四步的关键,不是技术上都能不能跑,而是把职责边界写清楚。
| 步骤 | 做什么 | 验收标准 |
|---|---|---|
| 1 | 跑通最小网页任务 | 能稳定打开、读取、回传结果 |
| 2 | 补移动端执行层 | App 动作有固定承接环境 |
| 3 | 把动作写进 Skills | 有条件判断和失败分支 |
| 4 | 回收到 Jumei.ai | 团队能复盘和交接 |
从规范角度看,W3C 的 WebDriver 也是把浏览器自动化抽象成程序可控制的接口。W3C WebDriver
Playwright MCP 和 Jumei.ai 怎么配合时的常见错误和排查方法
最常见的错误,不是命令装不上,而是架构边界一开始就画错了。
- 把移动端任务强行塞给浏览器层,结果网页动作能跑,App 任务落不了地。
- 把 Skills 写成超长步骤清单,但没有失败分支,导致一旦中断就没人知道下一步。
- 没有区分账号环境和执行环境,只看动作是否成功,不看后续是否能复盘。
- 把所有能力一次性全开,结果调试噪音太多,反而看不清最小链路。
说明接法在变稳
- 网页结果能稳定返回
- 移动端任务有固定承接环境
- 失败后知道谁补救
说明还在混层
- 浏览器层被迫处理 App 动作
- 任务失败后只靠群消息追人
- 执行完没有统一回收记录
排查顺序建议固定成三层。
- 先查 Playwright MCP 是否能稳定返回网页结果。
- 再查云手机动作是否能稳定复现。
- 最后看 Skills 是否把前后依赖写清楚。
Playwright MCP 和 Jumei.ai 怎么配合后怎么判断是否成功
是否成功,不看“功能很多”,而看是否形成了可复用的执行链。至少要满足四条:网页步骤能稳定跑、移动端步骤有明确承接环境、任务结果能被回收并复盘、失败后知道由谁处理。
| 检查项 | 成功信号 | 失败信号 |
|---|---|---|
| 浏览器层 | 能稳定读取网页状态 | 只能偶尔跑通 |
| 移动端层 | App 任务有固定环境承接 | 靠人工临时接手 |
| Skills 层 | 失败后有下一步规则 | 中断后没人知道如何补救 |
| 流程回收 | 结果能回到统一任务视角 | 执行完就散落在群消息里 |
成功 / 失败速查
- 成功:网页能稳定返回,App 有固定承接,Skills 有失败分支,结果能回收。
- 失败:浏览器硬扛 App,失败后靠群消息追人,执行完没有统一记录。
如果这四项里只能满足前两项,说明你接的是工具,不是执行架构。
试运行、验证与复盘
第一轮不要追求全量接入。更稳的 pilot 是挑一个网页任务、一个移动端任务、一个 Skills 流程串成最小样本,然后连续跑几天。
建议记录四个字段:
- 任务名
- 执行层
- 失败点
- 补救动作
试运行记录模板
- 任务名:
- 执行层:
- 失败点:
- 补救动作:
如果你准备把这套能力给运营团队用,最后还要再看一眼 数据监控分析 视角。
常见问题
Playwright MCP 能不能直接替代云手机?
通常不能。它更适合网页自动化,不适合直接覆盖 App 内动作。
Skills 是不是就是脚本?
不完全是。更适合把 Skills 理解成 SOP 编排层,而不是单纯的脚本文件。
为什么已经能跑网页了,还要补 Jumei.ai?
因为网页执行只是其中一层。团队协作、任务回收和后续复盘,通常还需要平台层来承接。
多账号任务一定要先上指纹浏览器吗?
不一定,取决于你是不是已经进入多账号网页环境管理阶段。浏览器层和移动端层不要混着判断。
Playwright MCP 最应该先验证什么?
先验证最小网页任务,比如打开页面、读取状态、回传结果,不要先做复杂业务链路。
什么时候再补云手机层?
当任务里已经有必须在 App 内完成的动作时,再补云手机层更合适。
团队什么时候算真正接入成功?
当网页层、移动端层和 Skills 层都能被同一套流程看见,并且失败后知道谁来处理时,才更接近成功。
总结
Playwright MCP 和 Jumei.ai 怎么配合,核心不是工具堆叠,而是执行分层。浏览器做浏览器该做的事,云手机做移动端该做的事,Skills 负责把 SOP 和结果回收串起来。
References