

核心要点
- OpenHands Quickstart 的目标不是“让模型聊天”,而是让 Agent 在受控环境里读代码、改文件、跑命令和完成开发任务。
- 开始前要准备运行环境、模型配置、仓库权限和一个足够小的测试任务。
- 第一个任务建议选文档修改、单元测试修复或小范围代码改动,不要直接交给它复杂线上问题。
- 验收时要看文件 diff、命令输出、测试结果和任务边界,而不是只看 Agent 的文字回复。
OpenHands Quickstart 是让开发者快速体验 AI 软件工程 Agent 的入门流程。它的重点不是问答,而是让 Agent 在一个开发环境里执行真实动作:查看项目、编辑代码、运行命令、解释失败原因,并把结果交给人类确认。官方文档把 OpenHands 描述为可通过终端或托管方式使用的开发 Agent 工具,研究论文也把它定位为能写代码、使用命令行和浏览网页的通用软件开发 Agent 平台。
这篇文章适合想了解“AI Agent 怎么真正进入开发流程”的中文团队。它也适合做出海社媒和自动化系统的团队参考:当你理解 OpenHands 这类开发 Agent 的执行边界后,也更容易理解 Jumei 为什么把 AI、浏览器环境、移动端云控和 SOP 执行放在同一套工作方式里讲。
参考资料主要来自 OpenHands 官方安装文档、OpenHands CLI 安装文档 和论文 OpenHands: An Open Platform for AI Software Developers as Generalist Agents。
开始前先确认是否适合这样做,以及 OpenHands Quickstart
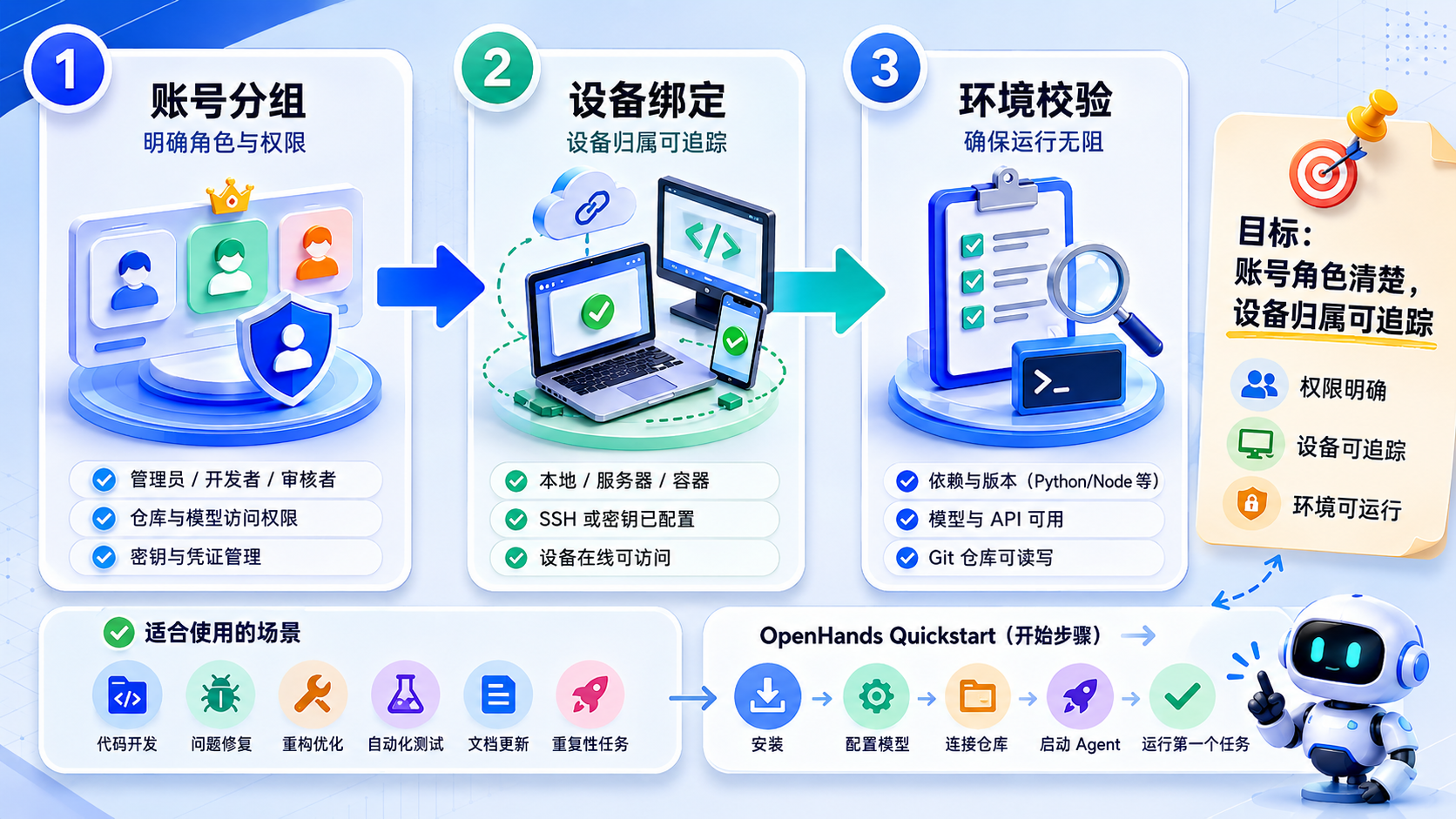
OpenHands Quickstart 更适合已经有开发环境、Git 仓库和明确小任务的人。比如让 Agent 阅读 README,修一个明显的测试失败,补一个简单函数,或者解释一个模块的运行方式。这类任务边界清楚,结果容易验收。
不适合的情况也很明确。不要一开始就让它处理生产事故、权限敏感操作、大规模重构或没有复现步骤的 bug。Agent 能执行命令和修改文件,意味着它也可能误改范围之外的内容。第一轮体验应该放在测试仓库、分支或沙盒环境中。
如果团队的目标是研究 AI 执行能力,可以把 OpenHands 看成开发侧样本。它解决的是“AI 如何在代码环境里执行”。而 Jumei 的AI 执行平台解决的是运营侧问题:AI 如何在浏览器、云手机和多账号环境里执行社媒、获客和客户承接任务。
| 适合做 OpenHands Quickstart | 不适合直接开始 |
|---|---|
| 有测试仓库和清晰小任务 | 只有一个模糊需求 |
| 能看懂 Git diff 和命令输出 | 不知道如何回滚改动 |
| 能提供模型配置和低权限环境 | 要直接接触生产密钥 |
| 目标是验证开发 Agent 执行能力 | 期待一次替代完整开发流程 |
前置准备
开始前至少准备四件事。第一是基础运行环境。根据官方文档,OpenHands 提供托管或本地使用方式,具体安装方式会随版本变化,最好以官方 Quick Start 和 CLI 文档为准。不要照搬旧博客里的命令。
第二是模型和密钥。Agent 需要可用的模型能力。你要提前确认模型服务、API Key、费用预算和网络访问是否正常。这里不建议把密钥写进仓库,也不要把生产环境凭据直接暴露给试验 Agent。
第三是测试仓库。选择一个可以回滚的项目,最好有 README、测试命令和清晰任务。不要把第一个任务放在复杂单体仓库里,否则你很难判断失败是环境问题、模型问题还是任务太大。
第四是验收标准。开始前就写清楚:它应该改哪个文件,跑哪条命令,输出什么结果,哪些目录不能碰。AI Agent 的核心不是“听起来完成了”,而是可验证地完成了。
OpenHands Quickstart 教程:从安装到第一个 Agent 任务的核心步骤
可以按这个顺序跑第一轮:
- 打开 OpenHands 官方文档,确认当前推荐的安装方式。
- 准备本地或云端运行环境,并配置模型凭据。
- 新建一个测试分支,确保 Git 工作区干净。
- 选择一个小任务,例如“修复 README 中过期命令”或“让某个简单测试通过”。
- 把任务描述写清楚,包括目标、限制、验收命令。
- 启动 Agent,让它读取项目并执行。
- 完成后检查 diff、测试输出和日志,再决定是否保留改动。
任务描述不要写成“优化这个项目”。更好的写法是:“请阅读 README,把安装命令更新为当前 package.json 中存在的命令。不要改源代码。完成后说明改动文件。”这种任务有边界,Agent 更容易做对,人也更容易验收。
如果你熟悉 LangGraph、CrewAI 或其他 Agent 框架,可以把 OpenHands 放在不同位置理解。LangGraph 更偏开发者编排 Agent 流程,CrewAI 更偏角色和任务协作,OpenHands 更强调软件开发环境里的执行。它们不是完全同类工具,比较时要看你要的是框架、工作流,还是可执行开发环境。
第一个任务可以用下面模板:
| 字段 | 示例写法 |
|---|---|
| 目标 | 修复 README 中已经失效的安装命令 |
| 可改范围 | 只允许修改 README.md |
| 验收命令 | 读取 package.json,确认命令名称存在 |
| 禁止事项 | 不要改源码,不要安装新依赖 |
| 输出要求 | 列出改动原因、文件路径和检查结果 |
这个模板看起来简单,但能显著减少误操作。OpenHands Quickstart 阶段,任务越明确,越容易判断 Agent 的实际能力。
常见错误和排查方法,以及 OpenHands Quickstart 排查顺序
第一个常见错误是环境没准备好。表现可能是命令找不到、依赖安装失败、模型无法调用、权限不足。排查时先不要怪 Agent,先手动跑一遍项目的安装和测试命令。
第二个错误是任务太大。比如让它“一次性重构整个系统”或“修复所有问题”。Agent 会尝试拆解,但上下文和验证都会变复杂。第一轮最好控制在 1 到 3 个文件范围内。
第三个错误是没有限制目录。开发 Agent 会根据任务探索项目,如果没有边界,可能改到你不希望它改的地方。建议明确写出“可以修改哪些文件”“不要修改哪些文件”“不能运行哪些命令”。
排查清单:
- 模型密钥是否正确配置。
- 当前分支是否干净,是否方便回滚。
- 依赖安装命令是否能手动成功。
- 测试命令是否存在,失败信息是否稳定。
- Agent 是否只修改了任务相关文件。
- 输出说明是否和实际 diff 一致。
如果排查仍然失败,可以按“环境、模型、任务、权限、验证”五步缩小范围。先确认项目本身能跑,再确认模型调用能成功,然后缩小任务范围,最后检查权限和验收命令。不要在同一次尝试里同时更换模型、仓库和任务,否则很难定位问题。
做完后怎么判断是否成功
成功不是 Agent 说“完成了”,而是你能用证据确认结果。最基础的证据是 Git diff。看它改了哪些文件,是否符合任务范围,是否引入无关改动。第二个证据是命令输出。测试、构建或 lint 至少要跑过一项和任务相关的验证。
第三个证据是可读说明。Agent 应该能说明它为什么这样改、验证了什么、还剩什么风险。如果说明很长但没有具体文件和命令,可信度就不够。
第四个证据是可回滚。第一次体验时不要直接提交到主分支。先让人类审查,再决定是否保留。AI 执行能力越强,越需要保留人工确认、权限控制和记录复盘。
这也是运营自动化和开发 Agent 的共同点。无论是在代码仓库里执行,还是在自动化运营里执行,关键都不是“AI 能不能动手”,而是动作是否有边界、过程是否可追踪、结果是否能验收。
常见问题
OpenHands Quickstart 适合完全没有开发经验的人吗?
不太适合作为零基础入门。它更适合已经能使用 Git、终端和项目依赖的开发者。没有这些基础,很难判断 Agent 做得对不对。
第一个 Agent 任务应该选什么?
优先选小而明确的任务。比如改文档、修一个简单测试、解释一个目录结构、补充错误提示。不要选没有验收标准的大任务。
OpenHands 和普通 ChatGPT 写代码有什么区别?
普通聊天工具主要输出建议和代码片段。OpenHands 更强调在开发环境里执行动作,包括查看文件、运行命令和修改项目。它更接近“可执行开发助手”。
需要把生产密钥交给 Agent 吗?
不建议。第一轮体验应该使用测试环境、低权限凭据或模拟数据。涉及生产密钥、客户数据和线上权限时,要单独做安全审查。
如果 Agent 改错文件怎么办?
先用 Git diff 看范围,再回滚不需要的改动。下次任务描述里要明确可改文件、不可改目录和验收命令。不要在脏工作区里直接运行。
OpenHands 能不能替代开发人员?
更现实的理解是辅助执行部分开发任务。它可以提高查找、修改和验证效率,但架构判断、需求取舍、代码审查和上线责任仍然需要人类负责。
为什么 Jumei 的文章会讲 OpenHands?
因为 OpenHands 代表一种“AI 进入真实执行环境”的思路。Jumei 关注的是同一类问题在运营侧的落地:让 AI 进入浏览器、云手机和账号工作区,执行社媒矩阵和获客任务。
总结
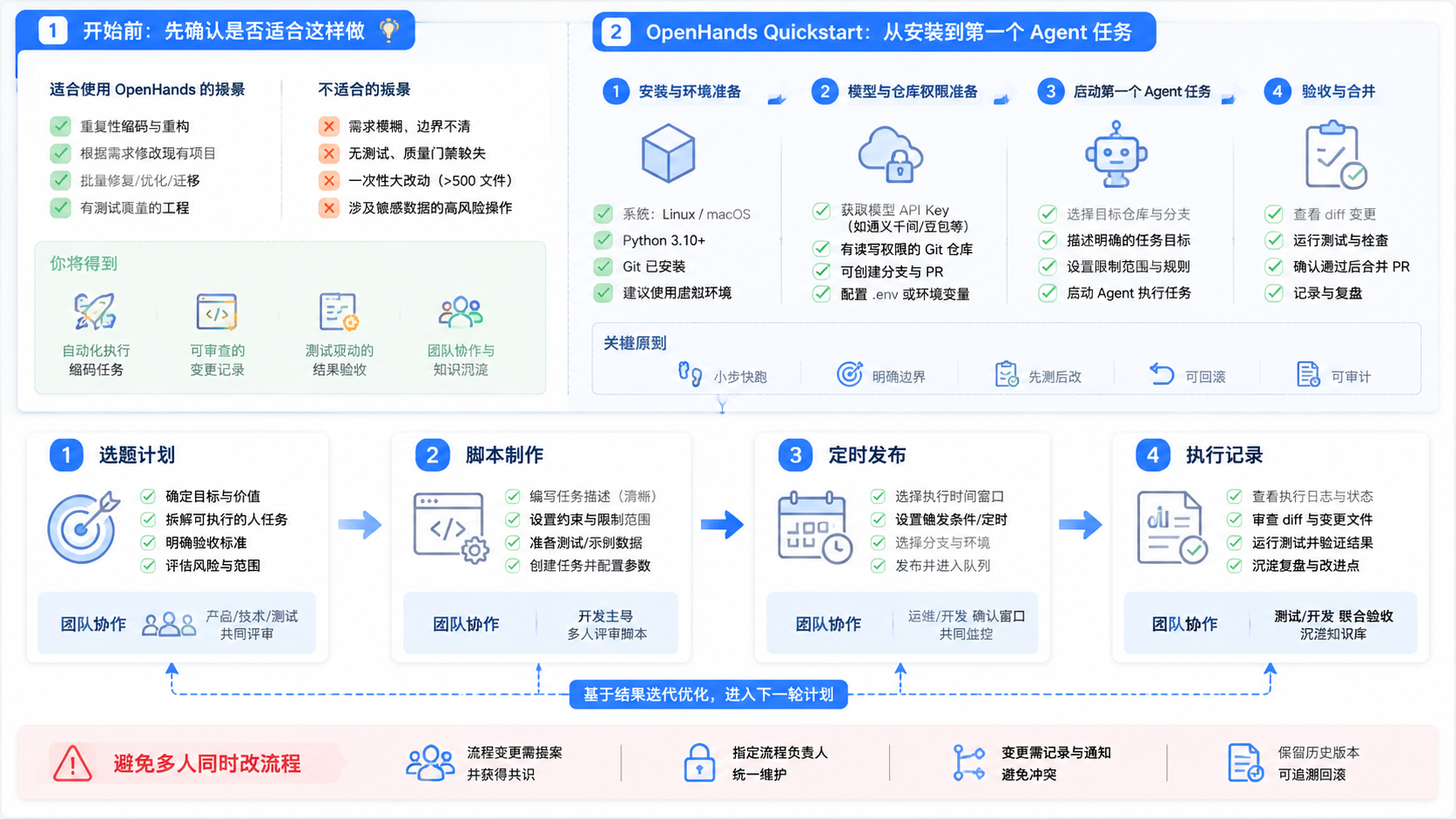
OpenHands Quickstart 的正确打开方式,是从一个小任务开始,先验证环境、权限、任务边界和验收流程。不要把它当成万能开发者,也不要只看文字回复。真正有价值的是它能否在受控环境里完成可检查的改动。
对中文团队来说,这类工具的启发不只在开发侧。AI Agent 要落地,必须连接真实执行环境,并保留人工确认、任务记录和复盘机制。无论是开发自动化,还是 Jumei 面向海外社媒矩阵的多账号管理,最终都要回到同一个问题:AI 做了什么,在哪里做,谁来验收,结果如何继续优化。

