在上一篇长文《Hermes Agent 核心原理解析》中,我们详细探讨了这款具备“自我进化”与“跨会话长期记忆”的新一代 AI 智能体框架。很多极客开发者、出海营销人员看完后都非常激动,希望能立刻让这位全天候在线的“数字员工”在自己的电脑上跑起来。
但在实际操作中,开源项目的部署往往伴随着各种 Python 环境冲突、网络报错和模型配置陷阱。本文将作为一份终极避坑指南,手把手带你完成从零基础环境搭建、源码克隆、向量数据库初始化,到最终无缝接入本地免费大模型(Ollama)的全部流程。这不仅是一篇教程,更是你走向 AI 自动化矩阵运营的第一步。
 一、 部署前的深度准备:硬核级环境清单
一、 部署前的深度准备:硬核级环境清单不要急着敲代码!无数人放弃部署的原因,往往是因为第一步的环境和硬件没搞清楚。Hermes Agent 作为新一代的 Autonomous Agent,其不仅需要运行简单的 Python 脚本,还需要处理复杂的向量检索和多模态理解。我们需要为它准备一个舒适的“工位”。
1. 硬件配置:你要为 AI 准备怎样的算力?
根据你选择的“大脑”(即底层大语言模型 LLM),对电脑的配置要求有天壤之别。这里我们将硬件需求分为“API 轻量派”和“本地重装派”。
| 运行架构模式 | 最低入场配置 | 极客级流畅配置 (推荐) | 硬件选型解析 |
|---|---|---|---|
| 云端 API 模式 (调用 OpenAI/Claude/DeepSeek) | CPU: 双核 内存: 8GB 显卡: 无要求 | CPU: 4核以上 内存: 16GB 网络: 稳定全局代理环境 | 最省钱的硬件方案。所有的算力压力都在云端服务器,你的本地电脑只负责发送指令和接收结果。适合轻量级办公自动化。 |
| 纯本地模型模式 (通过 Ollama 跑 Qwen/Llama) | 内存: 16GB 显卡: 8GB 显存 (如 RTX 3060) 或 Mac M1 | 内存: 32GB+ 显卡: 24GB 显存 (RTX 4090) 或 Mac M2/M3 Max | 零 Token 成本运行! 但重度吃显存(VRAM)。如果不达标,模型只能靠 CPU 强算,生成一个字需要几秒钟,毫无体验可言。 |
2. 底层软件依赖的“三板斧”
无论你是 Windows 还是 macOS,以下三个工具是必备的,建议提前下载并安装好:
- Python 3.10 或 3.11 版本: 请注意,过高的版本(如 3.12)可能会导致某些陈旧的 C++ 编译库(如部分向量数据库依赖)报错。
- Git 客户端: 用于直接从 GitHub 仓库拉取和更新最新代码。
- VS Code (Visual Studio Code): 全球最流行的轻量级代码编辑器,方便我们修改 .env 环境变量和自定义技能脚本。
二、 源码拉取与隔离环境构建 (Venv vs Conda)
如果你平时电脑里装了一堆乱七八糟的 Python 脚本,那么接下来的**“环境隔离”**将决定你能否成功运行 Hermes Agent。
Step 1: 克隆官方 GitHub 仓库
打开你的终端工具(Windows 建议按 Win 键搜索 `PowerShell` 或 `Git Bash`;Mac 搜索 `Terminal`),选择一个你硬盘空间充足的盘符(比如 D 盘),输入以下命令:
cd D:/AI_Projects
# 从官方仓库克隆 Hermes Agent 最新源码
git clone https://github.com/NousResearch/Hermes-Agent.git
# 进入项目根目录
cd Hermes-Agent
Step 2: 构建虚拟隔离环境 (Virtual Environment)
为什么要建虚拟环境?打个比方,Hermes 需要 1.0 版本的某个插件,而你电脑里的其他软件刚好装了 2.0 版本,如果你混着用,必定崩溃。这里推荐两种方式:
方式 A:使用原生 venv (最简单,无需额外装软件)
python -m venv venv
# 2. 激活虚拟环境 (Windows PowerShell 命令)
.\venv\Scripts\activate
# 2. 激活虚拟环境 (macOS/Linux 命令)
source venv/bin/activate
注意:激活成功后,你的命令行提示符最前面会多出一个绿色的 (venv) 字样,证明你现在在一个纯净的沙盒里了。
方式 B:使用 Anaconda / Miniconda (适合高级炼丹师)
如果你是资深 AI 玩家,建议用 Conda,管理底层 C 库更方便:
conda activate hermes_env
Step 3: 安装项目依赖 (Dependencies)
确保处于虚拟环境后,开始安装核心引擎:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
这个过程大约需要 3-10 分钟,它会自动为你安装用于构建 Agent 逻辑的框架(如 LangChain 或 LlamaIndex 的底层库)、网络请求库以及 MCP 协议依赖。
三、 核心大脑配置:云端 API 与本地 Ollama 深度接入
现在,你的 Hermes 拥有了躯体,但还没有灵魂。我们需要通过配置文件,给它装上“大脑”。
在项目根目录中,找到名为 .env.example 的文件。将其复制一份,并重命名为 .env。使用 VS Code 打开它。
策略 1:调用云端大厂 API(稳定、聪明,但烧钱)
如果你有 OpenAI 的 API Key,这是最快速跑通的方案。修改 `.env` 如下:
LLM_PROVIDER=openai
# 填入你的 API 密钥 (切勿泄露给他人)
OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxx
# 建议使用推理能力强的模型,Agent 的执行成功率极度依赖模型智商
DEFAULT_MODEL=gpt-4o
策略 2:纯本地化运行 Ollama(隐私、免费、无限白嫖)
对于需要 7x24 小时进行自动化监控、或者是使用类似 社媒自动化运营 插件疯狂发帖的用户,API 费用是一笔天文数字。本地化是唯一的解药。
我们需要借助强大的 Ollama 框架:
- 前往 Ollama 官网下载安装包并安装。
- 打开一个新的终端窗口(不用管刚才的 Hermes),输入:ollama run qwen2.5:7b(这里推荐阿里的千问开源模型,对中文理解极佳,且对显卡要求适中)。
- 等待模型下载完毕并在后台运行起来。如果想深入学习 Ollama 的显存分配技巧,强烈建议查阅《Agent 接入本地大模型 (Ollama) 深度配置指南》。
回到 Hermes 的 .env 文件,修改配置:
# Ollama 默认的本地服务端口
OLLAMA_BASE_URL=http://localhost:11434
DEFAULT_MODEL=qwen2.5:7b
四、 向量数据库 (Vector DB) 与长期记忆初始化
与旧时代的 AutoGPT 不同,Hermes Agent 被誉为“有灵魂”的原因在于它的记忆系统。它需要一个本地向量数据库(通常是 ChromaDB 或本地 SQLite)来存储它自我总结的技能(Skills)和你的偏好。
在第一次启动主程序前,我们需要初始化数据库结构:
python init_db.py
如果看到控制台打印 `[Success] Vector Database Initialized`,说明它的海马体已经准备就绪了。
五、 启动指令与终端人机交互实测
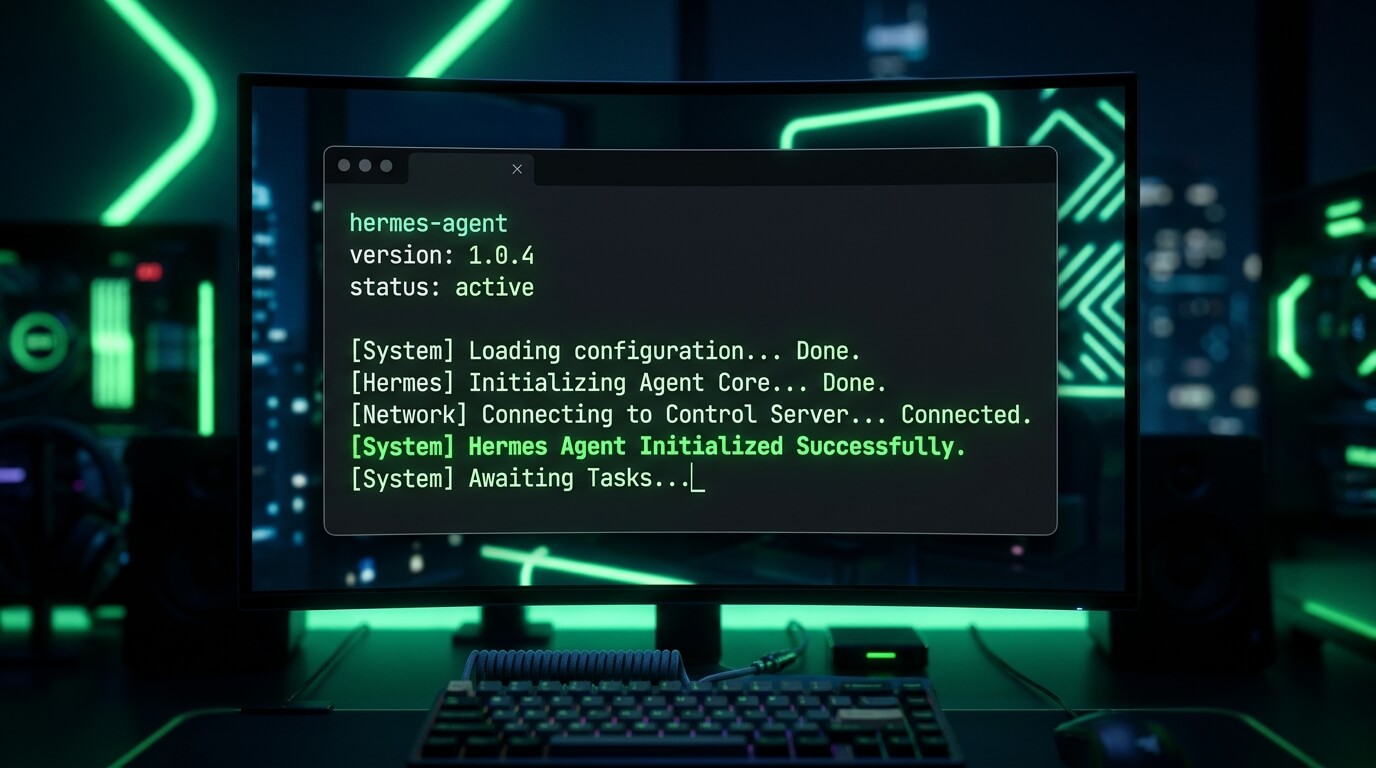
万事俱备!在激活了虚拟环境的终端中,输入唤醒指令:
此时,你的屏幕应该会出现类似科幻电影般的启动日志:
[LLM] Connected to Ollama Engine (Model: qwen2.5:7b)
[MEMORY] Vector DB connected. Loading 0 past session summaries.
[AGENT] I am ready. What is our task for today?
User >
你可以尝试给它下达第一个任务:
“帮我在当前目录下创建一个名为 test.txt 的文件,里面写上‘你好,世界’,然后读取这个文件的内容打印给我看。”
你会惊奇地看到它在终端中自我思考(Thought)、使用工具(Action: File System)、并验证结果(Observation),最终完美完成你的指令。
六、 企业级高阶玩法:从本地单机到云端矩阵运营
对于个人极客来说,在本地终端里跑通 Hermes Agent 已经是一个巨大的里程碑。但如果你是一个出海商家或 MCN 机构,你的目标绝不是“只让它建个文本文件”。
真正的商业化价值在于:规模化与脱机运行。
1. 接入通讯软件 (多端网关)
你总不能一直盯着电脑屏幕上的黑框框。我们可以通过配置 MCP (Model Context Protocol) 协议的通讯网关,将 Hermes 变成你的私人微信或电报助理。你可以随时在手机上给它发语音下发任务。详细的配置可以研读《Hermes Agent 接入 Telegram 完整配置指南》。
2. 结合云手机与指纹浏览器实现“矩阵获客”
当你想让 Hermes 登录 100 个 TikTok 账号去自动搜索同行、点赞截流、或者群发私信时,你在本地电脑是跑不动的,且极大概率会被平台封杀 IP 和设备特征。
在 2026 年的海外社媒实战中,高阶玩法是**“AI Agent 大脑 + 云端执行实体”**:
- AI 指挥官部署: 参考这篇《大规模 AI 矩阵本地集群部署教程》,将 Agent 部署在性能强劲的云服务器上(类似于 OpenClaw 底座架构)。
- 环境风控隔离: 让 AI 操控分布在云端的 私有化云手机 或者是 AI 指纹浏览器。
通过这种方式,即便 AI 疯狂执行 TikTok 多账号自动获客任务,每个操作也是在独立的干净环境中进行的,极大降低了封号率。这也是类似 jumei.ai(矩媒)这类企业级基础设施正在解决的核心痛点——不仅提供聪明的 AI 脑,还提供安全的云端执行手脚,彻底落地 社媒防封号的终极方案。如果你对这两种智能体生态有疑问,推荐阅读《Hermes Agent 与 OpenClaw 到底该怎么选?》。
七、 开发者“薅头发”报错级终极排雷指南 (FAQ)
不要慌,99% 的错误前人都踩过。如果你在上面的步骤中卡住了,请对号入座:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
1. 检查你是否真的在本地打开了 Ollama 软件?右下角任务栏有羊驼图标吗?
2. 打开你的浏览器,输入 `http://localhost:11434`,如果页面显示 "Ollama is running",说明正常;如果打不开,请检查你的系统防火墙或电脑代理软件(Proxy),是否拦截了本地环回端口。务必在代理软件中设置 `127.0.0.1` 绕过代理。
结语与下一步计划
至此,你已经成功跨越了一道高耸的技术门槛。看着自己的电脑屏幕里,一段代码像有生命一样在帮你执行任务,那种极客的成就感是无与伦比的。
然而,“部署成功”只是你 AI 自动化旅程的起点。在后续的进阶系列文章中,我们将为你拆解如何亲自为 Hermes Agent 编写 Python 自定义技能 (Skills Plugins),让它能无缝操作你指定的特定软件和网页。记得收藏本站,我们下期极客指南见!