

Key Takeaways
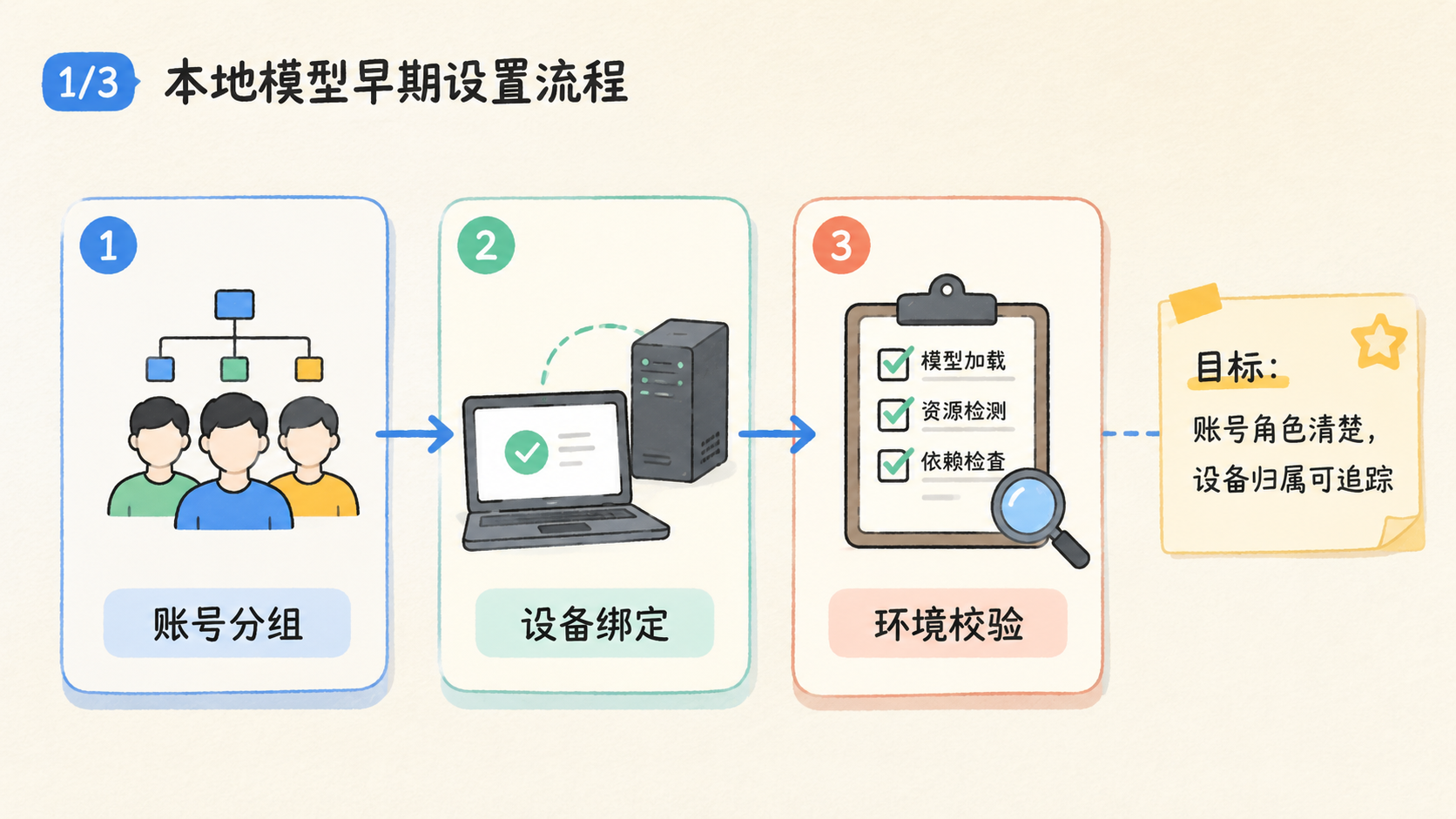
- Hermes Agent 本地模型能不能省钱,取决于任务量、硬件利用率、模型能力和维护成本。
- 本地模型适合高频、低风险、可容错的重复任务,不适合复杂推理、强实时和高准确性任务。
- 只看 API 单价容易误判,本地部署还要算 GPU、机器、电力、维护、排队和失败重跑成本。
- 如果 Agent 任务需要稳定速度,本地模型必须先做 7 天小流量试点。
- 最稳妥的方式通常是混合架构:简单任务走本地,关键判断和复杂任务走更强模型。
Hermes Agent 本地模型,是指把 Agent 的部分推理或生成任务放到本地机器、私有服务器或自建推理服务里执行,而不是全部调用外部 API。它可能省钱,也可能拖慢任务,关键看任务是不是足够高频、足够稳定、足够适合小模型处理。
如果只是偶尔运行 Agent,Hermes Agent 本地模型通常不一定划算。机器闲置、模型调参、部署维护和失败重跑都会变成隐形成本。相反,如果团队每天有大量低风险、格式固定、可批量处理的任务,本地模型才可能把单位成本压下来。
判断这件事不能只看“本地不花 token 钱”。更要看 4 个问题:任务量够不够大,硬件能不能吃满,模型能力够不够用,任务失败后重跑成本高不高。Google 关于有用内容的原则强调结果是否真正帮助用户。放在 Agent 里,就是不要只追求成本数字好看,还要看执行结果是否稳定、有用、可复盘。
Hermes Agent 本地模型是什么
Hermes Agent 本地模型可以理解为“把一部分 Agent 大脑放到自己控制的环境里”。它不等于完全离线,也不等于所有任务都必须本地跑。更常见的做法是把任务分层:简单分类、格式整理、草稿预处理走本地;复杂判断、关键决策、长链路推理走更强模型。
Ollama 的官方文档提供了本地运行模型和 API 调用的基础能力说明,适合作为理解本地模型工作方式的入口。参考 Ollama documentation 可以看到,本地模型通常涉及模型下载、运行环境和接口调用。对运营团队来说,这些都不是一次性配置,后面还会牵涉更新、监控和排障。
vLLM 官方文档则更偏向高吞吐推理服务。它强调推理服务、吞吐和部署能力,适合团队理解“本地模型不只是装一个模型”,还可能需要服务化、并发控制和资源调度。可以参考 vLLM documentation。
这就是很多人讨论 Hermes Agent 为什么爆火时容易忽略的地方。真正的问题不是“能不能本地跑”,而是“本地跑之后,Agent 是否仍然能按业务节奏交付”。如果速度变慢、失败率升高、维护变重,省下的 API 费用可能被运营成本吃掉。
什么时候能省钱,什么时候会拖慢任务
Hermes Agent 本地模型能省钱的前提,是任务量稳定且硬件利用率高。比如每天有 1,000 次以上固定格式处理,模型输出只需要分类、改写、摘要或初筛,本地模型就有机会降低边际成本。
会拖慢任务的情况也很常见。任务并发突然升高,机器排队会变长。模型能力不够,人工返工会增加。上下文太长,本地推理速度会下降。任务需要强推理,本地小模型可能反复失败。
可以用下面的表先判断:
| 判断项 | 更可能省钱 | 更可能拖慢 |
|---|---|---|
| 日任务量 | 1,000 次以上稳定运行 | 每天几十次、波动大 |
| 任务类型 | 分类、摘要、格式化、初筛 | 复杂推理、策略判断 |
| 容错空间 | 可人工抽检、可重跑 | 一次错误影响大 |
| 并发要求 | 可排队、可批处理 | 必须实时响应 |
| 硬件利用率 | GPU 或服务器长期使用 | 机器大部分时间闲置 |
| 维护能力 | 有人能看日志和性能 | 没人负责排障 |
如果 6 项里有 4 项落在“更可能省钱”,可以做小流量试点。如果有 3 项以上落在“更可能拖慢”,先不要把核心任务迁到本地模型。
Hermes Agent 本地模型适合谁,不适合谁
适合 Hermes Agent 本地模型的团队,通常已经有清楚的任务分层。它们知道哪些任务只是“预处理”,哪些任务才是“关键判断”。本地模型适合处理前者,不应该一开始就接管后者。
例如海外社媒矩阵团队,可以把评论初筛、素材标签、账号日报摘要、低风险内容改写交给本地模型。真正涉及账号策略、客户沟通、投放节奏和异常处理的部分,仍然需要更强模型或人工复核。
Jumei 的自动化运营和数据分析更适合放在流程层面理解。模型只是执行链路中的一环。团队需要知道任务从哪里来,结果流向哪里,失败后谁处理。
不适合本地模型的团队也很明确:
- 没有稳定任务量,只是偶尔试用 Agent。
- 没有人负责机器、模型和日志。
- 任务错误会直接影响客户、账号或收入。
- 任务需要长上下文、多轮推理和复杂判断。
- 团队还没有写清楚 SOP 和验收标准。
如果团队连“什么算成功输出”都说不清,本地模型不会解决问题。它只会把问题从 API 账单转移到部署和返工上。
有哪些实际使用场景
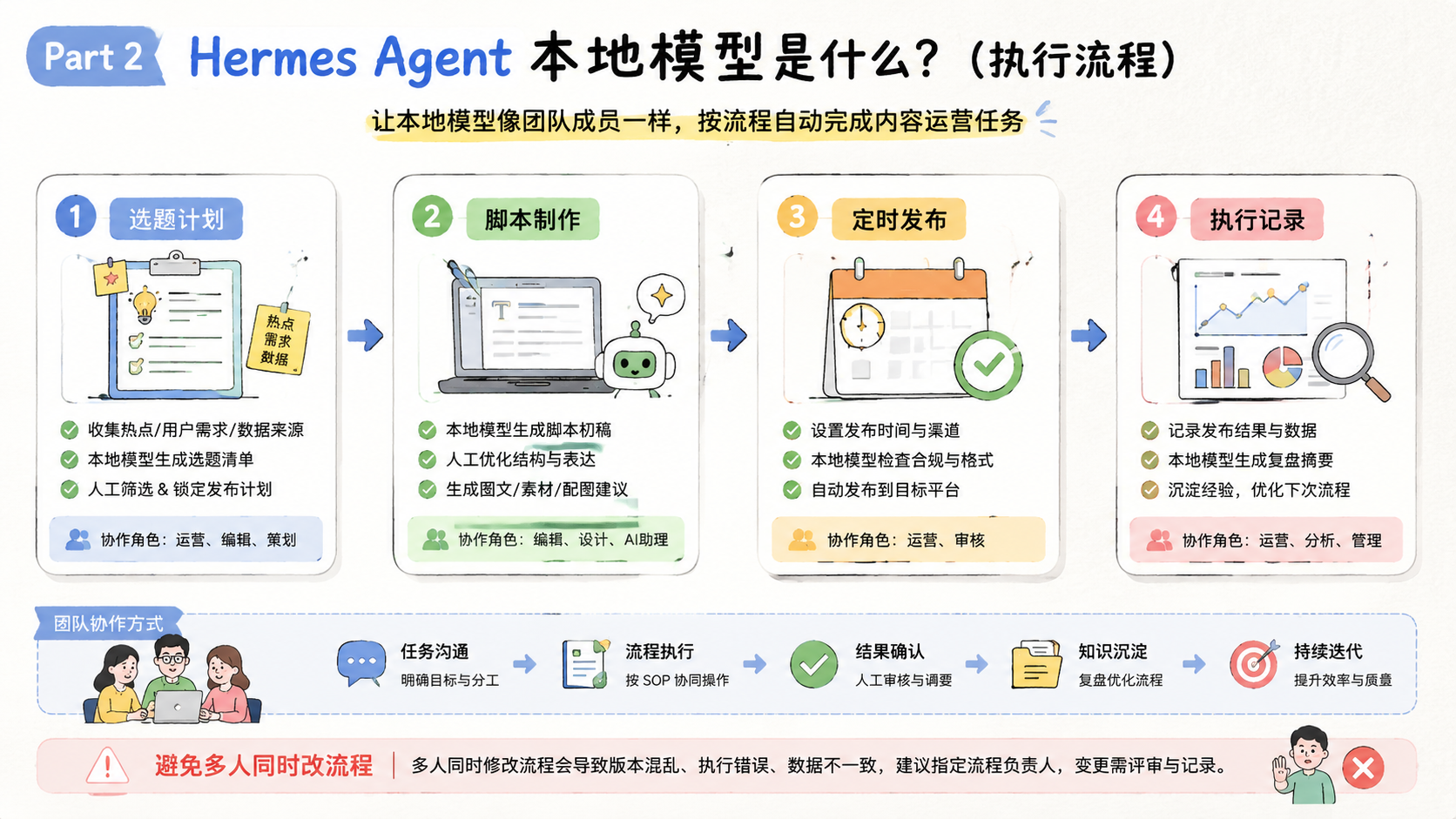
比较适合 Hermes Agent 本地模型的场景,通常是高频、低风险、结构稳定的任务。它们不要求模型每次都做复杂判断,只要求模型按规则完成大量重复动作。
可以从 5 类任务开始:
- 内容预处理:把素材拆成标题、标签、摘要和待发布字段。
- 评论初筛:把评论分成咨询、投诉、垃圾信息和可跟进线索。
- 账号日报:把多个账号的基础数据整理成运营摘要。
- SOP 辅助:根据固定流程生成检查项和下一步提醒。
- 低风险改写:对已有文案做语气统一、长度压缩或格式整理。
这些任务可以接入 Jumei 的多账号管理和社媒自动化运营平台。重点不是让本地模型单独工作,而是让它成为矩阵执行链路中的一个低成本节点。
不建议一开始就让本地模型处理高影响动作。比如客户承诺、账号异常判断、预算调整、平台规则解释和复杂策略建议。这些任务失败一次,可能需要人工花更长时间补救。
常见误区
第一个误区是只算 API 账单,不算总成本。本地模型需要机器、显卡、存储、监控和维护。即使不产生外部 token 费用,也会产生硬件和人力成本。
第二个误区是认为本地一定更快。本地推理速度取决于模型大小、硬件、并发和上下文长度。没有足够资源时,排队和超时会让 Agent 链路变慢。
第三个误区是把所有任务一次性迁移。正确做法是先拆任务等级,再逐步迁移。低风险任务可以先试,关键任务要保留人工复核。
可以用 3 档来分:
| 任务档位 | 示例 | 是否适合先本地化 |
|---|---|---|
| 低风险 | 标签、摘要、格式化 | 可以先试 |
| 中风险 | 评论分类、线索初筛 | 小流量试点 |
| 高风险 | 策略、承诺、异常处置 | 不建议直接本地化 |
第四个误区是忽略失败重跑。一个任务本地跑 1 次很便宜,但如果要重跑 3 次,再加人工检查,就不一定便宜。
Hermes Agent 本地模型应该怎么开始判断
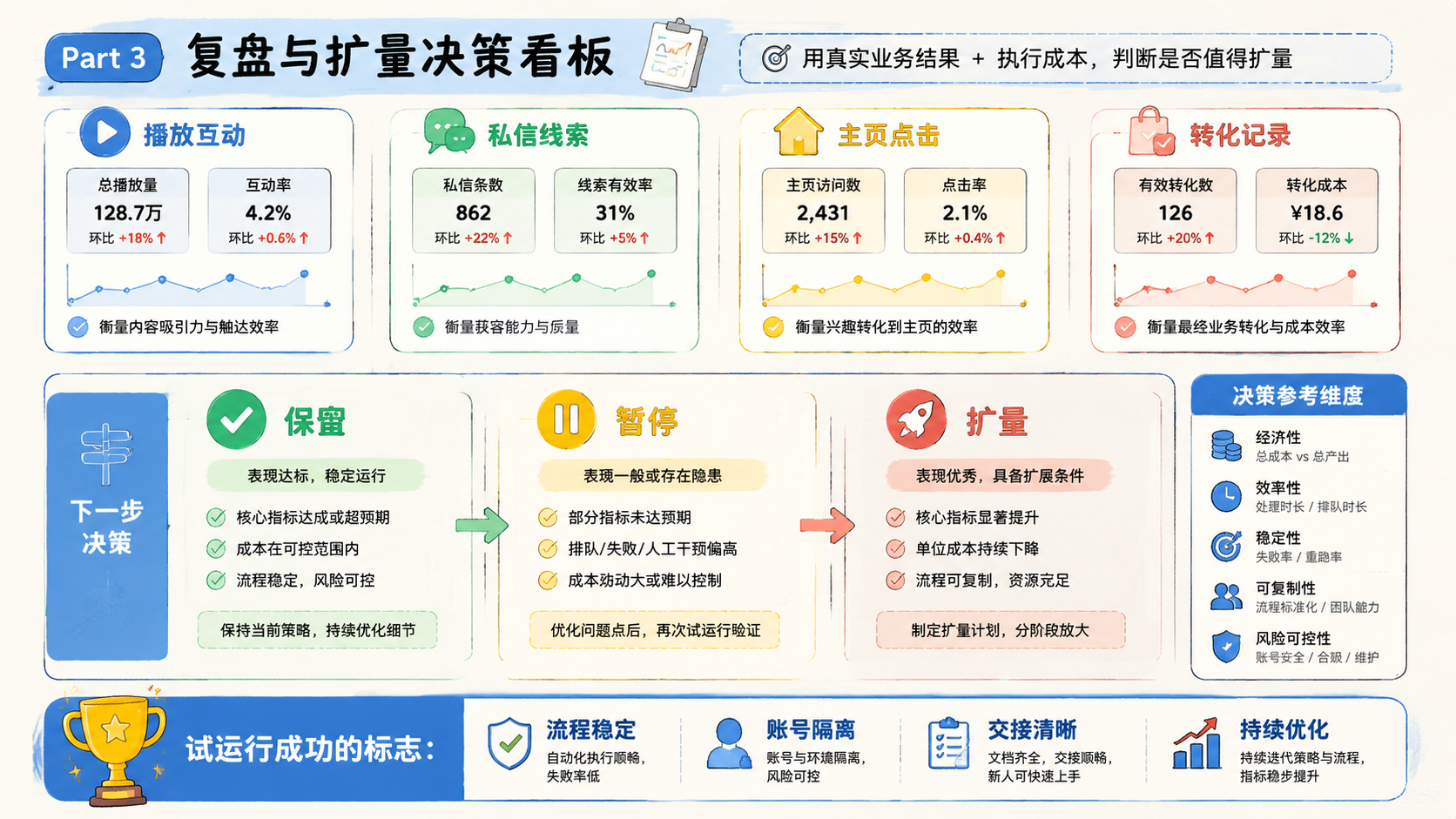
开始前先做 7 天试点,不要直接迁移完整链路。试点目标不是证明本地模型“能跑”,而是证明它在真实任务里不会拖慢团队。
建议记录 6 个指标:
| 指标 | 记录方式 | 判断意义 |
|---|---|---|
| 日调用量 | 每天任务次数 | 判断是否有规模 |
| 平均耗时 | 每次任务秒数 | 判断是否拖慢 |
| 排队时间 | 等待执行时间 | 判断并发压力 |
| 成功率 | 可用结果占比 | 判断返工成本 |
| 人工复核量 | 每天复核次数 | 判断隐形成本 |
| 重跑次数 | 失败后重试次数 | 判断真实成本 |
试点范围要小。建议先选 1 个流程、1 个模型、1 台机器或 1 组服务器。连续跑 7 天后,再比较本地成本、API 成本和人工成本。
如果本地模型只省了少量 API 费用,却增加了明显排队和复核,本地化就不值得扩大。如果低风险任务稳定、速度可接受、人工复核减少,才适合继续扩展。
Jumei 的工作方式页面适合用来理解执行流程。对团队来说,模型选择必须服从流程,而不是反过来让流程迁就模型。
常见问题
Hermes Agent 本地模型一定更省钱吗?
不一定。只有任务量稳定、硬件利用率高、失败返工少时,本地模型才可能省钱。低频任务通常不划算。
本地模型为什么会拖慢任务?
常见原因是硬件不足、并发排队、上下文太长、模型能力不够和失败重跑。速度要看完整链路,不只看单次推理。
什么任务最适合先本地化?
适合分类、摘要、格式整理、标签生成、低风险改写这类任务。它们高频、结构稳定,失败后也容易重跑。
哪些任务不建议本地模型直接处理?
不建议直接处理客户承诺、账号异常判断、预算调整、复杂策略和高影响动作。这些任务需要更强模型或人工复核。
本地模型和云端 API 能混用吗?
可以,而且通常更稳。简单任务走本地,关键任务走云端强模型,最后再用人工复核关键结果。
怎么判断是否该继续扩大试点?
看 6 个指标:调用量、平均耗时、排队时间、成功率、复核量和重跑次数。连续 7 天稳定,再考虑扩大。
本地模型需要专人维护吗?
只要进入正式流程,就需要有人负责模型、机器、日志和故障处理。没人维护时,本地模型很容易变成新的瓶颈。
第一步应该做什么?
先选一个低风险流程,记录 7 天数据。不要一开始迁移核心任务,也不要只凭 API 账单做决定。
总结
Hermes Agent 本地模型不是天然省钱方案,也不是天然拖慢方案。它的价值取决于任务类型、调用规模、硬件利用率、模型能力和团队维护能力。
如果任务高频、低风险、结构稳定,本地模型可以作为成本优化层。如果任务复杂、强实时、错误影响大,本地模型就可能拖慢 Agent 链路,甚至增加人工返工。
下一步不要先买机器,也不要先迁移核心流程。先选 1 个低风险任务,跑 7 天,记录 6 个指标。只有当速度、成功率、复核量和真实成本都说得过去时,Hermes Agent 本地模型才值得扩大使用。

