

Key Takeaways
- Hermes Agent 持久记忆不是把所有聊天记录永久保存,而是把任务目标、执行结果、异常原因和可复用经验整理成下一次能调用的上下文。
- SQLite 适合做轻量结构化存储,FTS5 适合做本地全文检索,会话总结适合把长过程压缩成可读、可追踪的记忆条目。
- 对多账号运营和海外社媒矩阵团队来说,记忆层要服务于 SOP 复用、账号隔离、异常复盘和人工接管,而不是让 Agent 无边界自作主张。
Hermes Agent 持久记忆,指的是让 Agent 在一次任务结束后,把有价值的信息沉淀下来,并在后续任务中按规则重新取用。它不是简单保存聊天全文,也不是把所有历史数据塞回模型上下文。更实用的做法,是把“这次任务做了什么、为什么这样做、哪里失败、下次如何避免”变成可检索、可审计、可删除的记录。判断 Hermes Agent 持久记忆是否成熟,要看它能否服务下一次执行,而不是看保存了多少文本。
这个能力之所以被关注,是因为很多 Agent 演示只解决了一次性任务。真正进入运营现场后,团队关心的是连续执行:今天处理一个账号,明天处理同类账号;本周修正了一个 SOP,下周不要再犯同样的错;某个页面结构变化后,所有相关流程都要知道异常。没有持久记忆,Agent 每次都像新员工。记忆设计不清楚,又容易把错误经验、敏感信息和过期规则一起带进下一轮。
对 Jumei 这类面向海外社媒矩阵运营的 AI 执行平台来说,持久记忆的价值在于把执行过程变成系统资产。浏览器、云手机、账号环境和工作流只是执行载体,真正能复用的是任务定义、执行日志、异常分类、人工修正和复盘结论。判断 Hermes Agent 持久记忆是否值得做,不能只看“能不能记住”,而要看它是否能帮助团队更稳定地复制 SOP。
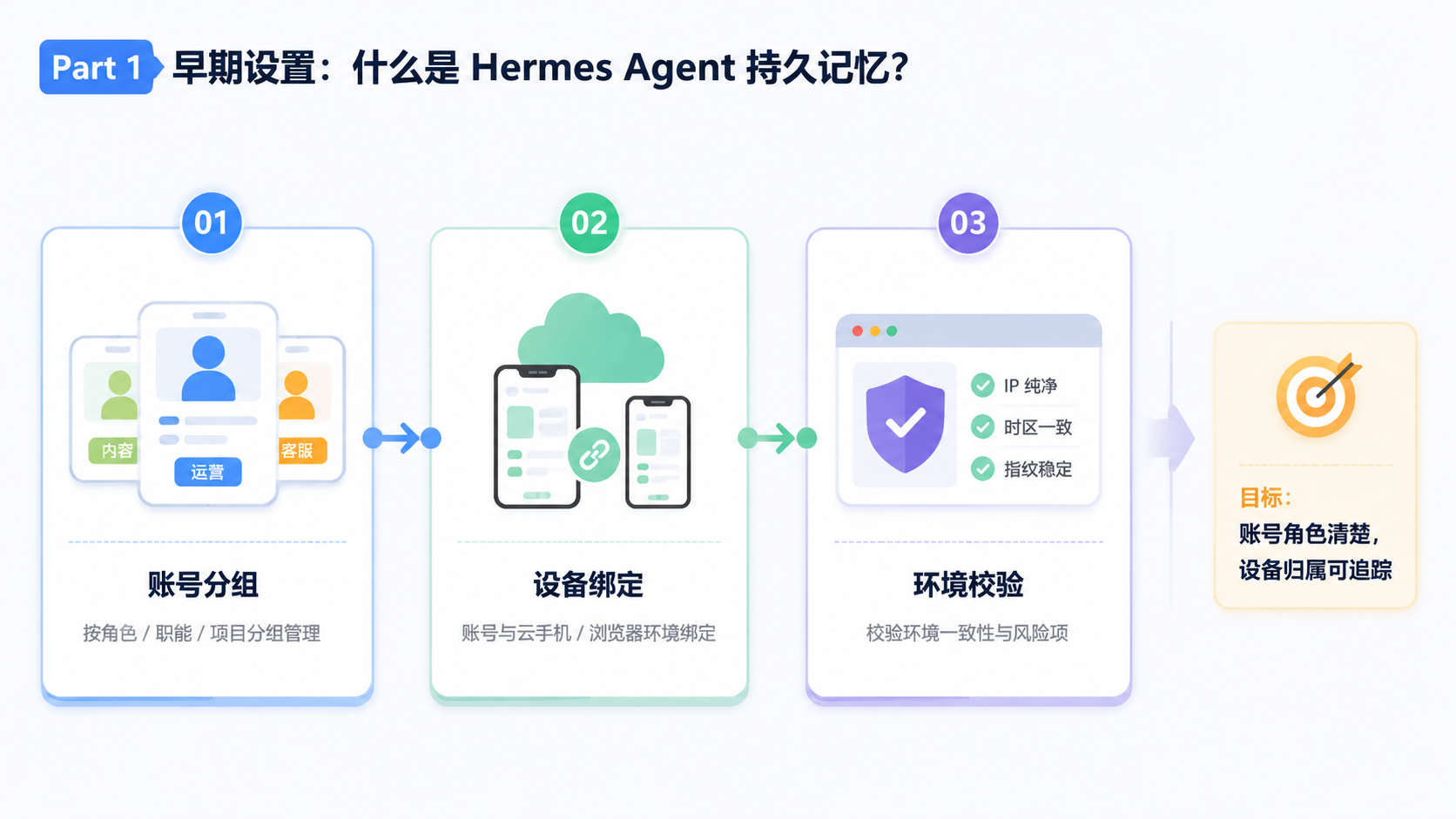
Hermes Agent 持久记忆到底是什么
Hermes Agent 持久记忆可以拆成三层:记录层、检索层和总结层。记录层保存原始任务事实,比如任务编号、账号环境、输入内容、执行步骤、结果状态和错误原因。检索层负责在新任务开始前找到相关历史。总结层把冗长过程压缩成短文本,让人和模型都能快速理解。SQLite 的文件型数据库说明可参考 SQLite 官方文档,FTS5 的全文检索能力可参考 SQLite FTS5 官方文档。
SQLite 常被用来做本地轻量数据库,因为它部署简单、文件化、便于随任务环境迁移。对早期 Agent 项目来说,它比直接上复杂数据库更容易控制边界。FTS5 是 SQLite 的全文检索扩展,适合在本地记忆里按关键词、任务描述、错误类型查找历史记录。会话总结则解决上下文太长的问题,把一次执行压缩成“可复用结论”。
这三者组合起来,适合做一个小而稳的记忆原型。比如一次 Instagram 资料检查任务失败,系统不一定要保存全部页面截图和所有中间文本,但应该保存失败页面、触发条件、人工接管动作和最终修正方式。下次遇到类似任务时,Agent 可以先检索历史,再决定是否继续、重试或交给人工。
边界也要讲清楚。持久记忆不是永久记忆,更不是无条件共享记忆。多账号、多客户、多团队场景下,记忆必须跟用户、账号、浏览器环境和工作流权限绑定。某个账号的异常经验,不能随意进入另一个客户的执行环境。某个运营人员的临时备注,也不能默认变成全局规则。
Hermes Agent 持久记忆适合哪些场景
适合做持久记忆的场景,通常有三个特征:任务会重复、结果需要复盘、历史经验能减少下一次执行成本。比如账号资料巡检、内容发布前检查、线索字段整理、页面状态监控、工作流失败原因分类。这些任务不一定复杂,但频率高、细节多,人工长期处理容易遗漏。
不适合的场景也很明确。如果任务本身没有稳定目标,只是希望 Agent “自己想办法增长”,持久记忆很难发挥价值。记忆只能放大已有流程,不能替团队定义业务目标。如果历史记录没有人工校验,错误做法也会被记住,后续反而更难排查。
更适合沉淀为记忆
- 重复出现的页面异常和处理方式。
- 账号执行环境里的固定限制和注意事项。
- 人工接管后的修正步骤。
- SOP 版本变更后的新规则。
- 任务完成后的结果摘要和复盘标签。
不应直接写入记忆
- 未经确认的一次性猜测。
- 敏感凭证、验证码、私密聊天内容。
- 过期平台规则和临时页面状态。
- 没有来源的运营结论。
- 跨客户、跨账号共享后会造成混淆的信息。
对海外社媒矩阵团队来说,记忆层要和 多账号管理 放在一起理解。一个浏览器代表一个账号或一组隔离环境时,记忆也应跟随这个边界。账号 A 的历史失败,最多作为同类任务的参考,不应该自动影响账号 B 的执行动作。这样做的目的不是保守,而是让责任链清楚。
为什么 SQLite、FTS5 和会话总结能组成轻量方案
SQLite 的优点是简单、可控、容易备份。Agent 原型阶段,团队通常还没确定最终的数据结构。如果一开始就接入复杂数据库,字段、权限、迁移和运维都会压住试点速度。SQLite 更适合先把记忆表设计清楚:任务表、事件表、总结表、标签表、版本表。结构稳定后,再考虑是否迁移到中心化数据库。
FTS5 的价值在检索。很多记忆不是靠精确 ID 找回来的,而是靠“这类错误之前遇到过吗”“这个页面状态怎么处理过”“这个账号组有没有类似限制”。全文检索可以把任务标题、错误描述、人工备注和总结内容放在一起查。它不替代权限系统,但能让本地记忆更容易被调用。
会话总结负责降低上下文成本。一条完整执行日志可能很长,包括模型思考、页面观察、动作记录、错误重试和人工接管。每次都把全文交给模型,成本高,也容易引入噪声。更稳的做法是保留原始日志,同时生成短总结。新任务优先读取总结,必要时再回查原始记录。
| 组件 | 适合保存什么 | 主要价值 | 注意事项 |
|---|---|---|---|
| SQLite | 任务、事件、标签、总结、版本 | 结构清楚,便于本地试点 | 需要设计权限和清理策略 |
| FTS5 | 错误描述、任务说明、人工备注 | 快速查找相似历史 | 不能替代精确过滤 |
| 会话总结 | 关键结论、失败原因、下次动作 | 降低上下文长度 | 必须保留来源和时间 |
| 原始日志 | 完整执行过程 | 审计和问题追踪 | 不宜全部塞回上下文 |
如果把三者放到 Jumei 的执行体系里,SQLite 更像本地学习缓存,FTS5 是查找历史经验的入口,会话总结是给 Agent 和运营人员看的任务卡片。真正执行动作仍然要走工作流、权限和执行器,不应该因为记忆里出现过某个做法,就跳过平台边界。
一套可落地的 Hermes Agent 持久记忆字段
做记忆层时,不建议一上来追求复杂。先把字段做少,但必须能追踪来源、环境和结果。最小可用结构可以从五类字段开始:身份字段、任务字段、环境字段、结果字段、复盘字段。
身份字段包括用户、团队、账号、浏览器环境、工作流 ID。它解决“这条记忆属于谁”。任务字段包括任务标题、输入摘要、目标页面、SOP 版本。它解决“这条记忆从哪里来”。环境字段包括平台、设备类型、执行载体和权限等级。它解决“这条经验适用在哪些环境”。结果字段记录成功、失败、停止、人工接管。复盘字段记录原因、修正动作、下次建议和是否可复用。
建议的记忆写入流程
- 任务开始前:按用户、账号、工作流和关键词检索相关历史。
- 执行过程中:只记录关键状态变化、异常和人工接管点。
- 任务结束后:生成短总结,标注成功、失败或待确认。
- 人工复盘后:把确认过的经验升级为可复用记忆。
- 定期清理:删除过期规则、敏感片段和错误总结。
这套流程和 自动化运营 的关系很紧。自动化不是让 Agent 无限制执行,而是把可重复动作放进受控流程。记忆写入也一样,不能因为模型生成了一个总结,就默认它是长期规则。更稳的方式是把记忆分成“观察记录”“待确认建议”“已确认规则”三类。
常见问题和错误做法
最常见的错误,是把所有历史聊天都当成记忆。这样做看似完整,实际会让检索变慢、上下文变脏,也容易把临时判断误用到新任务里。持久记忆应该优先保存可复用信息,而不是保存所有文本。
第二个错误,是不做账号和客户隔离。多账号运营里,一条记忆可能只适用于某个账号、某个浏览器环境或某个时间段。缺少隔离字段后,Agent 检索到历史也很难判断能不能用。对 AI 指纹浏览器 场景来说,环境边界和记忆边界要一起设计。
第三个错误,是忽略人工复盘。Hermes Agent 自我进化更适合理解为“基于执行结果的规则修正”,不是让模型自动把每次输出都当成真理。没有人工确认的记忆,最多作为参考。真正影响后续执行的规则,应有来源、版本和负责人。
第四个错误,是只记成功,不记失败。失败原因往往比成功结果更有价值。页面变更、登录过期、字段缺失、权限不足、任务目标不清,都应该被标注出来。下一次执行前,Agent 先看到这些失败模式,就能更早停下或请求人工确认。
FAQ
下面这些问题,重点回答 Hermes Agent 持久记忆在真实运营里怎么判断、怎么试点、怎么避免误用。
常见问题:Hermes Agent 持久记忆怎么判断要不要做
1. Hermes Agent 持久记忆和普通聊天记录有什么区别?
普通聊天记录偏向完整保存对话。Hermes Agent 持久记忆偏向保存可复用经验。它需要结构化字段、检索规则、权限边界和清理机制。能被下一次任务可靠调用的信息,才值得进入记忆层。
2. 为什么不直接把全部历史塞进上下文?
因为上下文越长,噪声越多,成本越高。很多历史对新任务没有帮助,还可能带来过期规则。更好的方式是先检索,再读取摘要,必要时再打开原始日志。
3. SQLite 适合生产环境吗?
这取决于规模和协作方式。SQLite 很适合本地试点、单机缓存和轻量记忆原型。如果团队需要跨用户实时共享、复杂权限和高并发写入,就要评估中心化数据库。早期可以先用 SQLite 验证字段和流程。
4. FTS5 是不是必须使用?
不是必须,但对文本型 Hermes Agent 持久记忆很有帮助。任务错误、人工备注、会话总结往往不是固定枚举,全文检索能更快找到相似历史。即便使用 FTS5,也要先按用户、账号和工作流过滤,避免跨边界检索。
5. 会话总结应该由谁确认?
低风险任务可以自动生成总结,但影响后续执行策略的总结,最好由运营负责人或流程负责人确认。确认后的总结才能升级为稳定规则。未确认总结应标注为参考信息。
6. 记忆会不会让 Agent 更容易犯老错误?
会有这个风险,所以要区分原始记录、失败记录、待确认建议和已确认规则。错误经验不能直接进入执行层。好的记忆系统不仅记住成功,也要能标记“这个做法不要再用”。
7. 多账号团队怎么开始试点?
先选一个低风险工作流,比如页面巡检、资料字段检查或线索格式整理。每次任务只保存少量字段:账号环境、任务目标、结果、失败原因、人工修正、下次建议。连续跑一到两周后,再看 Hermes Agent 持久记忆是否减少重复错误。
8. Jumei 这类平台适合把记忆放在哪里?
更适合放在执行平台的任务和账号边界内。浏览器、云手机和工作流都应该有对应记录。团队可以在 工作方式说明 中理解任务如何被拆分,再把记忆作为复盘层接进去。
参考资料
总结
Hermes Agent 持久记忆的核心,不是“让 Agent 记得更多”,而是“让 Agent 记得对下次执行有用的东西”。SQLite、FTS5 和会话总结是一套轻量起步方案,适合先把任务事实、检索能力和复盘摘要跑通。
真正落地时,团队要优先设计边界:谁的记忆、哪个账号的记忆、哪个工作流的记忆、是否已经人工确认、什么时候应该清理。没有这些边界,记忆越多,系统越难控。
对海外社媒矩阵运营来说,持久记忆应服务于 SOP 复制、账号隔离、异常回收和团队复盘。它不是替代运营判断,而是把已验证的执行经验放进下一次任务,让 AI 执行平台逐步从一次性演示,变成能持续改进的运营基础设施。

