

Key Takeaways

- 先明确任务边界,再判断是否进入安装、接入或自动化执行。
- Hermes Agent 自我进化 需要写成可检查清单,不能只停留在概念解释。
- 浏览器、云手机、账号、素材、日志和复盘字段要提前对齐。
- 小范围试运行通过后,再把流程沉淀成团队模板。
- Hermes Agent 自我进化必须经过记录、验证和人工验收,不能自动放权。
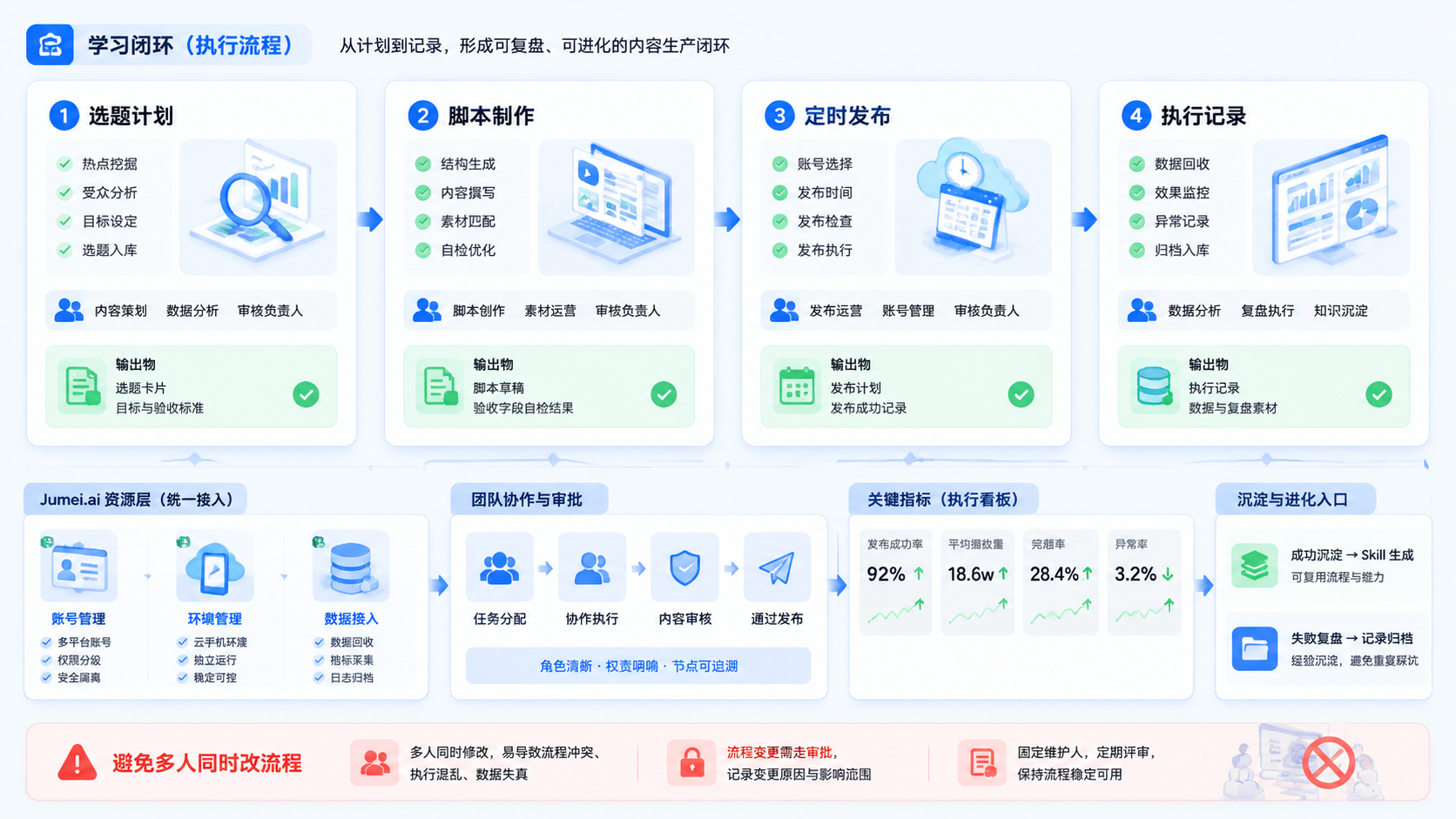
Hermes Agent 自我进化不是让系统凭空变聪明,而是把任务执行、失败原因、修正动作和新 Skill 生成连接成一个闭环。它的重点不是一次性生成很多能力,而是让每次执行都留下可复盘的信息。下一次遇到相似任务时,系统能用更清楚的步骤处理。
这类能力适合有重复任务、明确验收标准和稳定复盘机制的团队。如果团队还没有任务模板和失败记录,直接谈自我进化容易变成概念。更实际的做法是先建立学习闭环,再讨论 Skill 是否值得沉淀。
Hermes Agent 自我进化先看学习闭环
学习闭环至少包含四个环节:执行任务、记录结果、分析失败、更新能力。缺少任何一环,都不能算稳定自我进化。只会执行,不会复盘,系统会重复犯错。只会生成 Skill,不做验收,能力会越来越难管理。
判断闭环是否有效,要看它能否回答三个问题:上次失败在哪里,这次改了什么,下次遇到同类问题怎么做。如果答案都能被记录和复用,才有继续扩大价值。
| 检查项 | 应该确认什么 | 不通过时怎么处理 |
|---|---|---|
| 权限 | 文件、账号、工具调用是否必要 | 收缩权限,只保留最小访问 |
| 输入 | 素材、指令、配置是否清楚 | 先补字段,再运行任务 |
| 环境 | 浏览器、云手机、容器是否归属明确 | 固定环境 ID 和负责人 |
| 输出 | 结果是否可复盘 | 增加日志和验收字段 |
Hermes Agent 自我进化里的 Skill 生成不应该变成能力堆积
Skill 生成的目标是沉淀高频、稳定、可验收的能力,而不是把每次临时处理都保存下来。一个好 Skill 应该有清楚输入、明确输出、可解释步骤和失败处理方式。没有这些边界,Skill 越多,团队越难知道该用哪一个。
更稳的流程是先让人工确认任务确实重复,再让 Agent 生成候选 Skill,最后由负责人验收。通过后进入测试环境,连续多次稳定后再放进正式任务。这样能避免“自动生成能力”变成新的维护负担。
如果任务要进入团队运营,可以先和 Jumei.ai 工作方式 对齐,把账号、环境、任务和复盘放在同一套流程里。涉及网页端动作时,可以使用 AI 指纹浏览器 管理浏览器环境。涉及移动端任务时,再结合 云手机 做设备归属和执行隔离。
Hermes Agent 自我进化如何接入运营执行
接入运营执行时,学习闭环必须连接账号、素材、环境和数据复盘。Agent 可以总结失败原因,也可以生成新的执行步骤,但它需要知道任务发生在哪个账号组、使用哪个环境、输出影响哪个业务目标。
如果使用 Jumei.ai 承接运营侧流程,可以把浏览器、云手机、账号分组和执行记录放到统一视图里。Hermes Agent 负责从执行经验中提炼 Skill,Jumei.ai 负责让团队看见这些 Skill 用在什么场景、产生什么结果。
- 定义目标:写清楚任务要解决什么,不解决什么。
- 确认边界:账号、设备、目录、权限和输出都要有负责人。
- 隔离试跑:先用测试素材,不直接碰正式账号。
- 记录过程:保存关键日志、错误类型和人工确认点。
- 复盘再扩大:通过连续试运行后再进入更多账号组。
常见错误和验收规则
第一个错误是把自我进化理解成自动放权。实际上越能生成能力,越需要验收。第二个错误是只看成功案例,不看失败样本。没有失败样本,系统不知道该避免什么。第三个错误是把所有经验都写成 Skill,导致能力库臃肿。
验收规则要简单:新 Skill 是否解决重复问题,是否有明确输入输出,失败时是否可解释,是否能被另一个人复现。如果不能满足这些条件,就先保留为复盘记录,不要直接进入正式能力库。
- 不要把未知来源能力直接装进正式环境。
- 不要让 Agent 在没有停止条件的情况下反复重试。
- 不要把账号、设备、浏览器环境和素材混在一个临时目录里。
- 不要只保存成功结果,失败原因和人工介入点同样重要。
Hermes Agent 自我进化的验收表
可以把 Hermes Agent 自我进化拆成 5 个验收项,每项 20 分。任务复现 20 分,失败原因记录 20 分,修正动作 20 分,新 Skill 输入输出 20 分,人工验收结论 20 分。总分低于 80 分,不进入团队模板。低于 60 分,说明闭环还不稳定,只能保留为实验记录。
建议至少做 3 轮试运行。第 1 轮只处理 1 个样例任务。第 2 轮加入 1 个失败样本。第 3 轮让另一个成员按同样文档复现。每轮都记录任务 ID、输入文件、失败步骤、修正动作、Skill 版本和复盘结论。若 30 分钟内无法解释失败原因,就暂停生成新 Skill。
2026 年以后,Agent 工具更容易把经验自动沉淀成能力。越容易沉淀,越要限制入口。Hermes Agent 自我进化应当服务于稳定流程,而不是把每次临时修正都写进能力库。
外部参考和复盘字段
系统和容器层可以参考 Microsoft Learn 的 WSL 安装文档 以及 Docker 官方文档。如果文章或团队文档要对外发布,可以参考 Google Search Central 的 有帮助内容指南,确保内容提供真实判断标准,而不是堆命令和口号。
复盘字段建议包括:任务 ID、账号组、设备环境、浏览器环境、输入素材、执行人、开始时间、结束时间、失败步骤、处理动作、复盘结论和下一次调整。字段越稳定,后续接入 Jumei.ai 数据分析 时越容易判断流程价值。
常见问题
这类文章里的风险清单应该给谁看?
风险清单应该给实际安装、配置和验收的人看,也应该给业务负责人看。执行同学需要知道哪些目录、权限、账号和外部依赖不能随便放开。负责人需要知道哪些风险会影响交付结果、账号归属和团队复盘。只给技术同学看,容易漏掉运营边界;只给业务同学看,又容易漏掉执行细节。
第三方 Skill 能不能直接装?
不建议直接装到正式工作环境里。更稳的做法是先放进隔离测试环境,确认它需要哪些权限、会访问哪些文件、会调用哪些外部服务、会产生哪些输出。测试通过后,再决定是否进入团队模板。这样即使出问题,也不会影响真实账号、正式素材和生产任务。
怎么判断 Hermes Agent 自我进化闭环是真的有用?
关键不是它会不会生成新内容,而是它能不能把失败原因、修正动作和下一次执行连接起来。如果每次失败后都只是重新跑一遍,那不算闭环。真正有用的闭环应该能留下记录,说明上次为什么失败,这次改了什么,下次遇到同类问题该怎么处理。
需要把所有日志都保存吗?
不需要保存所有低价值噪声,但关键节点必须保存。至少要保留任务开始、输入读取、工具调用、输出生成、错误发生和人工确认这些节点。日志太少无法排查,日志太多没人看。比较实际的做法是保留摘要字段,再把完整日志归档到可追溯目录。
和 Jumei.ai 配合时,哪些字段最重要?
最重要的是账号组、设备环境、浏览器环境、任务阶段、执行状态、失败原因和复盘动作。对海外社媒矩阵运营来说,结果不是一个孤立文件,而是和账号、素材、环境、发布时间、数据表现关联在一起。字段越清楚,后续越容易判断是否扩大。
什么时候应该暂停自动化?
当失败原因无法解释、账号归属不清、权限边界混乱、输出无法复核时,就应该暂停自动化。继续扩大只会把问题复制到更多账号和任务里。先把一个小流程修到稳定,再接更多环境,这比一次性铺开更安全。
这些检查会不会拖慢上线?
短期看会多花时间,长期看能减少返工。没有检查清单时,问题通常在真实执行后暴露,排查成本更高。把风险、字段和验收标准提前写清楚,可以让团队更快判断哪些任务适合自动化,哪些任务还需要人工处理。
Hermes Agent 自我进化第一版流程完成后下一步做什么?
下一步不是立刻扩大,而是做复盘。看任务是否稳定、日志是否可读、失败是否可定位、结果是否对业务有用。如果这些都成立,再把同类任务抽成模板,逐步接入更多账号、设备或 Skills。
总结
Hermes Agent 自我进化不能只看生成了多少 Skill。Hermes Agent 自我进化要看失败是否被记录,修正是否可复现,能力是否经过人工验收。
Hermes Agent 自我进化 的核心不是把概念讲热闹,而是让团队知道什么时候可以继续,什么时候应该暂停。只要任务边界、权限、环境、日志和复盘字段清楚,后续接入 Skills、浏览器和云手机都会更稳。
如果你正在搭建海外社媒矩阵执行流程,可以先把一条低风险任务跑通,再接入 Jumei.ai 自动化运营 做分组、执行和复盘。这样工具链会服务于业务流程,而不是反过来制造新的不确定性。

