

Key Takeaways
- OpenClaw 成本优化不是单纯换便宜模型,而是把任务分层、缓存、备用模型和人工确认放到同一套流程里。
- 模型选择要按任务风险和输出要求分级,不能所有步骤都用同一个高成本模型。
- 缓存适合稳定、重复、可复用的输入,不适合频繁变化或需要实时判断的内容。
- 备用模型要先做质量验证,再进入自动化流程,不能只因为便宜就直接替换主模型。
OpenClaw 成本优化,指的是在使用 OpenClaw 跑 Agent 任务时,通过模型分级、缓存复用、备用模型和执行边界设计,把不必要的模型调用、重复推理和失败重试降下来。
这件事不是简单找一个更便宜的模型。真正的成本来自三部分:模型调用成本、任务失败后的重跑成本,以及团队人工排查成本。如果只看单次模型价格,很容易把问题看窄。
对中文团队来说,OpenClaw 成本优化更适合从小任务开始。先确认哪些任务需要高质量推理,哪些任务只是格式整理,哪些任务可以复用历史结果。再决定主模型、轻量模型、缓存和备用模型怎么配。
如果团队还在了解 OpenClaw 是什么 或正在看 OpenClaw 教程,可以先把成本优化当成“执行流程设计”的一部分,而不是安装完成后的附加项。这样后面接入 Jumei.ai 的云手机、AI 指纹浏览器和账号矩阵任务时,成本边界会更清楚。
参考资料方面,内容质量可以对照 Google Search Central 的 helpful content 说明,Agent 工具调用可以参考 OpenAI Agents SDK 文档,上下文和工具连接可以参考 Model Context Protocol 文档。这些资料不能替代具体业务测试,但能帮助理解任务、工具和上下文的基础关系。
开始前先确认是否适合做 OpenClaw 成本优化
OpenClaw 成本优化适合已经有重复 Agent 任务的团队。比如每天生成内容计划、整理竞品资料、检查页面、归纳执行日志、生成运营 SOP,或者根据固定规则处理一批文件。
如果任务只是偶尔执行一次,优化空间通常不大。你花很多时间配置缓存和备用模型,可能还不如直接完成任务更划算。
更适合优化的任务,一般有三个特征:
- 输入格式相对稳定。
- 输出标准可以检查。
- 失败后会产生明显的重跑或人工排查成本。
不适合直接优化的任务也要提前排除。比如强依赖实时判断、输入每次都完全不同、结果没有明确验收标准,或者失败成本很高的任务。这里不建议为了省钱强行换模型。
对 Jumei.ai 用户来说,可以先从低风险流程验证。比如让 OpenClaw 生成账号分组建议、内容检查表、执行复盘摘要,再观察是否稳定。不要一开始就把账号动作、批量发布或高权限操作交给备用模型。
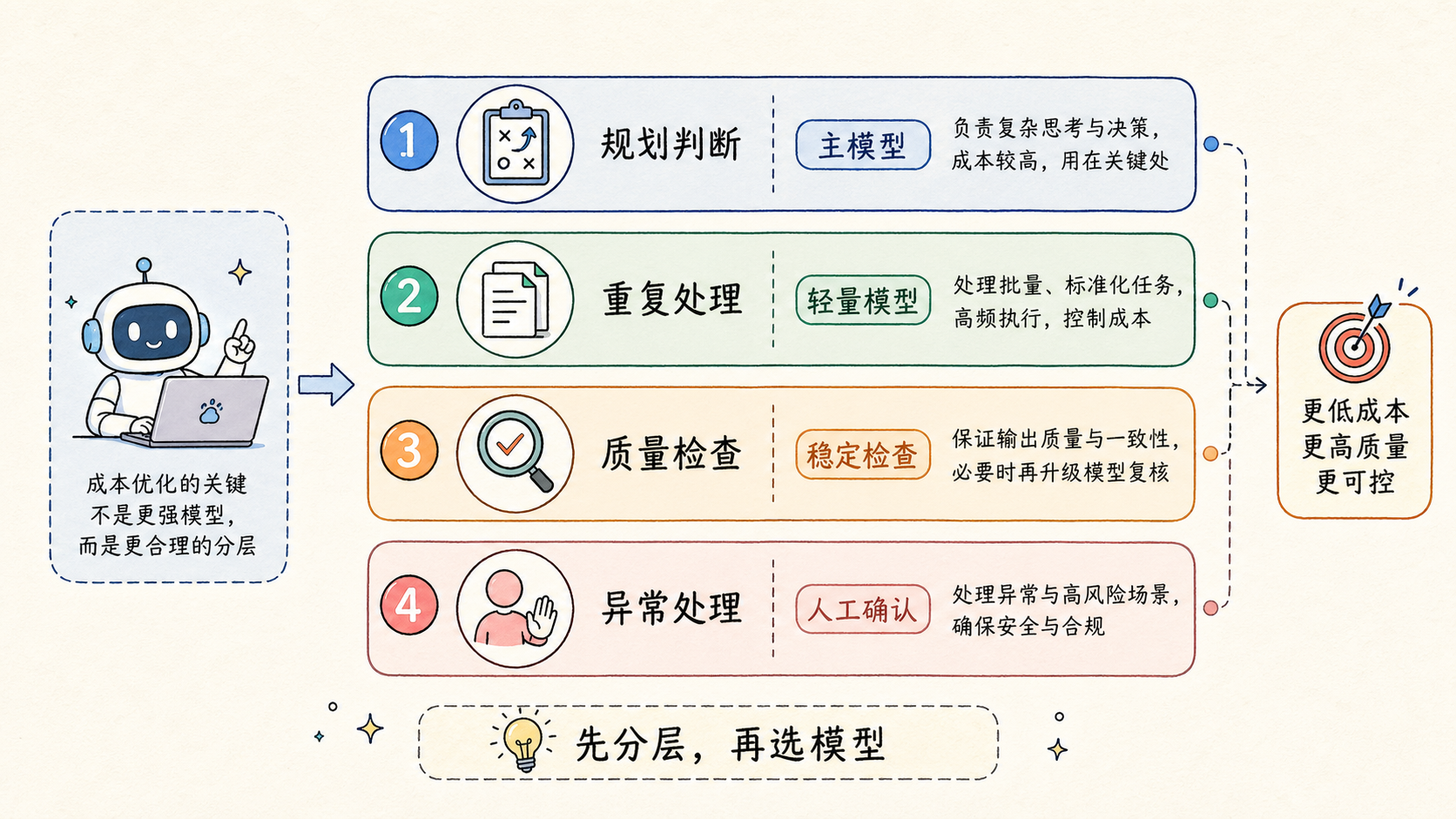
OpenClaw 成本优化:先把任务分层
模型选择的第一步,是把任务分层。不是所有步骤都需要最强模型,也不是所有步骤都能用轻量模型。
可以把任务分成三层。
第一层是理解和规划任务。它需要读懂目标、约束和上下文,适合用更稳定的主模型。比如把用户需求拆成执行计划,判断任务风险,设计完整 SOP。
第二层是格式化和重复处理任务。它更多是按规则输出,不需要太多复杂判断。比如把数据整理成表格,把日志归类,把固定格式的内容改写成统一模板。这类任务可以考虑轻量模型。
第三层是检查和兜底任务。它负责发现错误、判断是否需要重跑、或者把异常交给人工。这里不一定总要最强模型,但必须稳定。否则它会把错误放过去,后面成本更高。
OpenClaw 任务分层表
| 任务层级 | 适合模型 | 成本控制重点 |
|---|---|---|
| 规划判断 | 主模型 | 少跑但跑准,减少后续返工 |
| 重复处理 | 轻量模型 | 批量任务控制单次调用成本 |
| 质量检查 | 稳定模型 | 避免低质量结果进入下一步 |
| 异常处理 | 主模型或人工 | 只处理真正需要判断的异常 |
这样分层后,OpenClaw 成本优化才有基础。否则团队容易出现两个极端:要么所有任务都用高成本模型,要么为了省钱全部换成便宜模型,结果质量下降后反而增加人工成本。
模型选择怎么配:主模型、轻量模型和备用模型
模型选择建议从“任务结果要承担什么责任”开始,而不是从价格开始。
主模型适合负责关键判断。比如任务拆解、策略生成、复杂内容检查、错误归因和最终审核。它的价值是减少方向性错误。
轻量模型适合负责重复动作。比如标题归类、格式整理、简单摘要、固定字段提取和低风险改写。它的价值是降低高频调用成本。
备用模型不是“便宜模型”的同义词。备用模型应该用于主模型不可用、速度不稳定、成本超出预期,或者某类低风险任务可以稳定替换的场景。它必须先经过小样本测试。
一个可执行的配置思路是:
- 先选一个主模型处理完整流程。
- 记录每个步骤的输入、输出和失败原因。
- 找出高频但低判断难度的步骤。
- 用轻量模型替换这些步骤。
- 用备用模型跑同样样本,对比质量和重试次数。
- 只把稳定通过的部分放进自动化流程。
这套方法比直接问“哪个模型最便宜”更可靠。因为真正影响成本的,不只是单价,还有错误率、重试率、人工修正时间和上下文长度。
缓存怎么用:哪些内容值得缓存
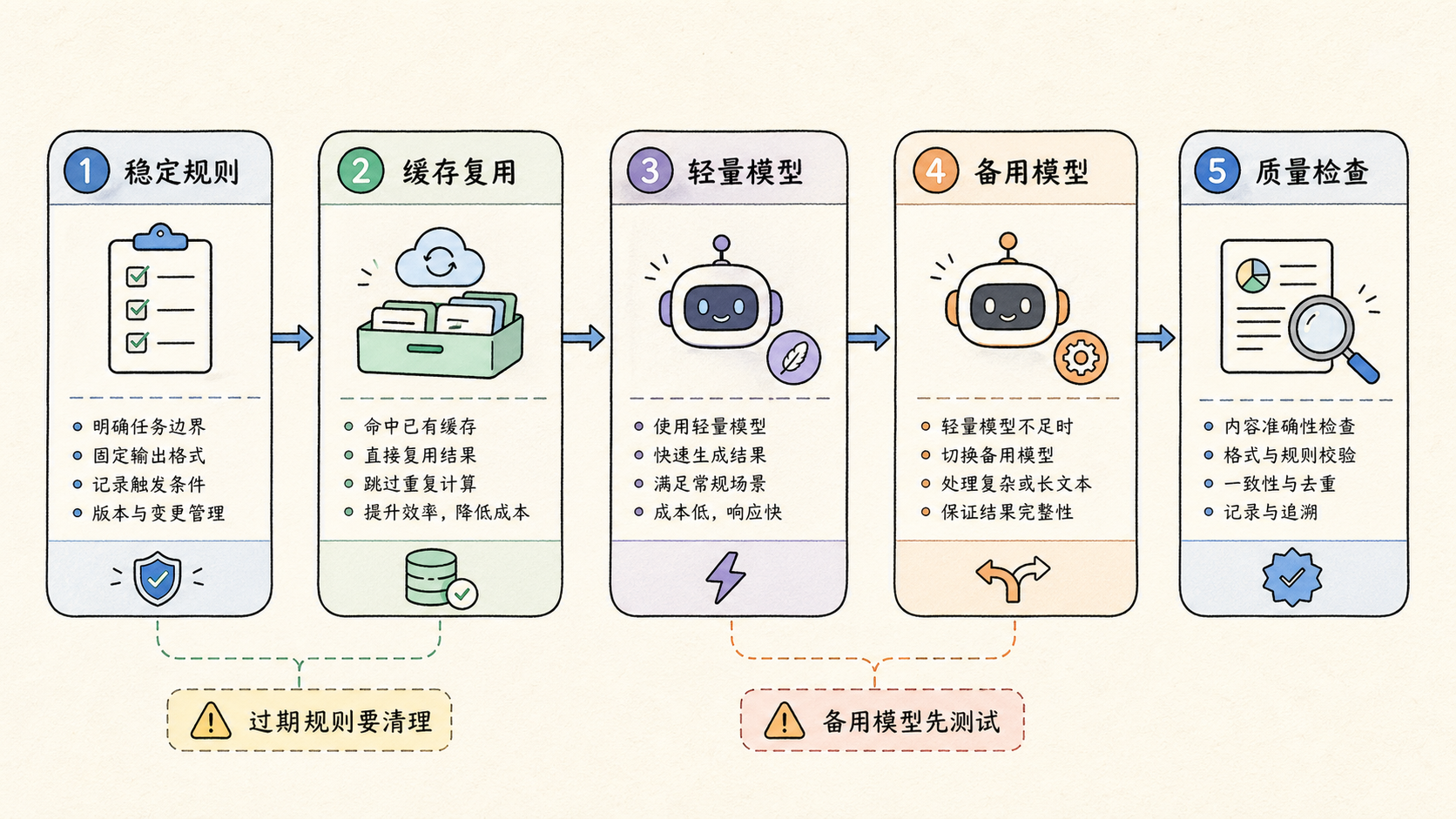
缓存的作用,是减少重复推理。它适合稳定输入,不适合每次都变化的判断。
值得缓存的内容通常包括:固定品牌规则、常用输出格式、产品说明、字段映射、检查清单、低变化的知识片段、已经确认可复用的中间结果。
不适合缓存的内容包括:当天数据、实时反馈、账号状态、临时策略、尚未确认的结论,以及可能影响安全或权限判断的信息。
适合缓存
- 品牌语气和写作规范
- 固定输出格式
- 常用检查清单
- 已确认的任务模板
不建议缓存
- 过期执行结果
- 敏感账号信息
- 未验证结论
- 频繁变化的数据
缓存也需要版本意识。规则更新后,旧缓存要能被替换。否则 Agent 可能继续按照旧规则执行,表面看省了成本,实际增加了错误成本。
一个实用做法是给缓存加来源和更新时间。团队至少要知道:这条规则从哪里来,什么时候确认,是否还适用,谁可以修改。
OpenClaw 成本优化指南:核心配置步骤
配置 OpenClaw 成本优化,可以按下面顺序推进。
- 选择一个低风险重复任务。不要从最复杂的业务流程开始。
- 用主模型完整跑一遍,记录每一步输入、输出、耗时和失败点。
- 把流程拆成规划、执行、检查、异常处理四类。
- 找出可以换轻量模型的步骤,例如格式化、摘要和字段整理。
- 设定缓存对象,只缓存稳定规则和可复用模板。
- 选择备用模型,先用历史样本做对比测试。
- 给每一步设置停止条件。结果不确定时,交给主模型或人工。
- 每周复盘一次成本、质量和重试率。
这八步的重点不是配置很多模型,而是让每个模型有清楚职责。主模型负责判断,轻量模型负责重复处理,备用模型负责稳定替换,人工负责关键确认。
如果你在 Jumei.ai 里做海外社媒矩阵,可以先让 OpenClaw 处理内容检查、账号分组建议和 SOP 草稿。等质量稳定后,再把部分流程连接到 Jumei.ai 执行环境。这样能避免一开始就把模型成本和账号执行风险绑在一起。
常见错误和排查方法
第一个错误,是只看模型单价。便宜模型如果导致更多重试、更多人工修正,整体成本可能更高。
第二个错误,是缓存太多。缓存过期规则会让 Agent 反复犯旧错误。缓存应该服务稳定流程,不应该保存一切内容。
第三个错误,是备用模型没有测试就上线。备用模型至少要跑一组真实样本,比较输出质量、格式稳定性、失败类型和人工修正时间。
第四个错误,是没有记录失败原因。没有日志,就不知道成本来自哪里。可能是提示词太长,可能是上下文重复,也可能是任务本身不适合自动化。
排查时可以按这个顺序看:
- 哪一步调用次数最多?
- 哪一步重试次数最多?
- 哪一步最常需要人工修改?
- 哪些输入可以复用?
- 哪些输出可以用规则检查?
如果这些问题答不上来,先不要继续换模型。先把流程记录补齐,再谈优化。
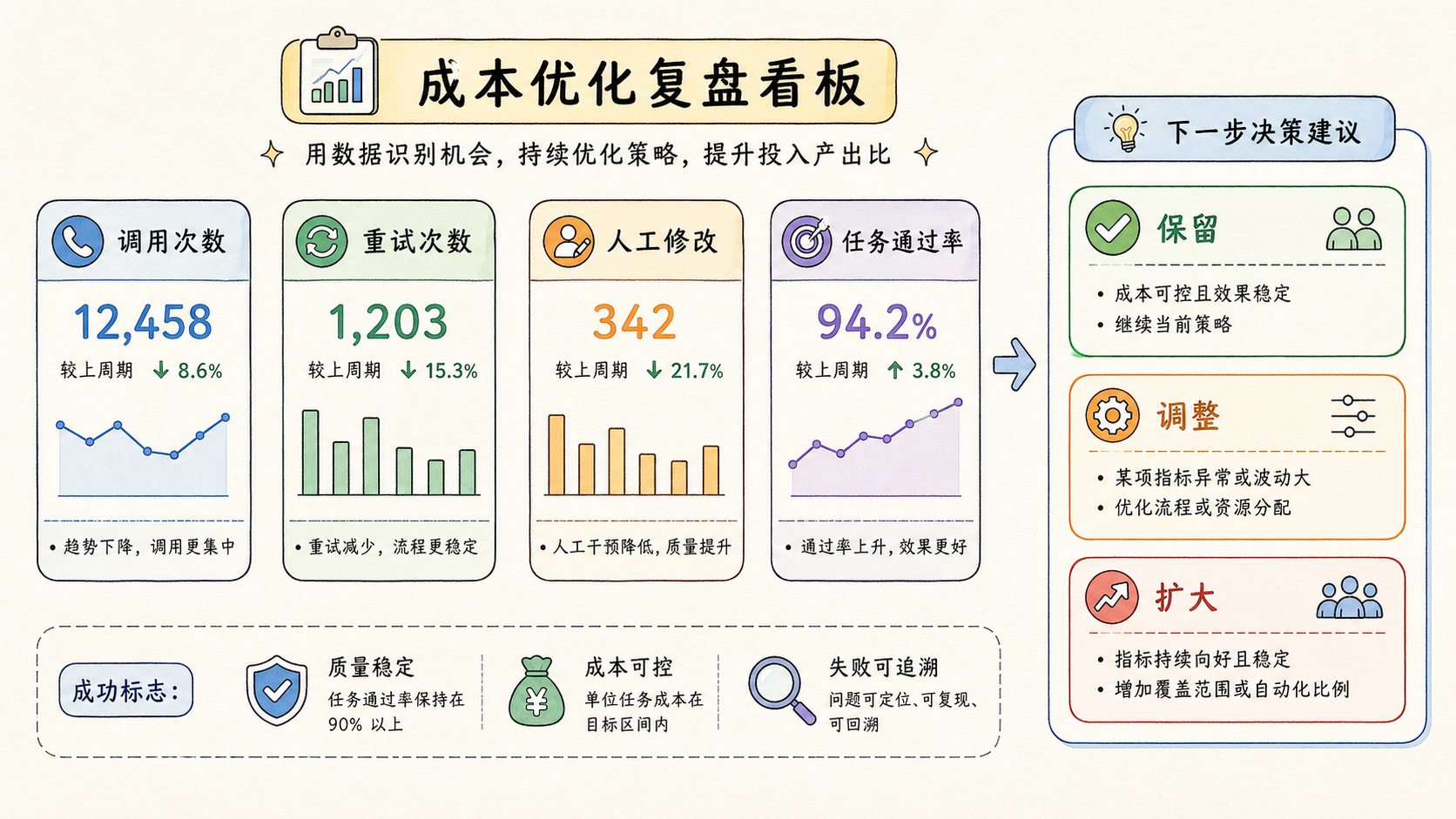
做完后怎么判断是否成功
OpenClaw 成本优化是否成功,不能只看费用下降。还要看质量、速度和可维护性。
一个合格的优化结果,通常会出现四个变化:重复任务调用减少;低风险任务不再占用主模型;失败原因更容易定位;人工确认集中在关键节点。
验收指标
| 指标 | 看什么 | 不达标时怎么处理 |
|---|---|---|
| 质量 | 输出是否符合检查标准 | 回到主模型或调整任务边界 |
| 成本 | 高频步骤是否降本 | 检查是否有重复上下文和无效重试 |
| 速度 | 批量任务是否更稳定 | 拆分任务或加入缓存 |
| 复盘 | 失败原因是否清楚 | 补充日志和停止条件 |
如果费用下降但人工修正增加,不能算成功。如果速度变快但质量不稳定,也不能直接扩大。真正可用的 OpenClaw 成本优化,是让团队在可控边界内减少浪费,而不是把风险藏起来。
常见问题
OpenClaw 成本优化是不是只要换便宜模型?
不是。换模型只是其中一步。更重要的是任务分层、缓存复用、备用模型测试和失败记录。否则便宜模型可能带来更多重试和人工修正。
OpenClaw 安装完成后就要马上做成本优化吗?
不建议马上大改。可以先用主模型跑通一个低风险任务,记录真实流程,再决定哪些步骤值得优化。
什么任务最适合用轻量模型?
格式整理、简单摘要、字段提取、固定模板改写和低风险分类比较适合。复杂判断、最终审核和异常归因更适合主模型或人工确认。
缓存会不会影响结果质量?
会有可能。缓存如果保存了过期规则或错误结论,会影响后续结果。所以缓存需要版本、来源和更新时间。
备用模型应该怎么选?
先用真实样本测试。比较输出质量、格式稳定性、失败类型和人工修正时间。只有稳定通过的任务,才适合切到备用模型。
OpenClaw 和 Jumei.ai 怎么配合?
OpenClaw 更偏 Agent 工作流组织,Jumei.ai 更偏执行环境。可以先让 OpenClaw 生成方案、检查表和 SOP,再逐步接入 Jumei.ai 的账号矩阵和云手机执行流程。
成本优化做到什么程度可以扩大?
当低风险任务质量稳定、重试可控、失败原因能追溯,并且人工确认集中在关键节点时,可以考虑扩大。
总结
OpenClaw 成本优化的核心,不是追求最低模型单价,而是让不同任务用合适的模型、合适的缓存和合适的备用策略。
更稳妥的顺序是:先跑通小任务,再记录流程;先分清任务层级,再替换模型;先验证备用模型,再进入自动化;先建立日志和停止条件,再扩大到团队流程。
如果你只是偶尔使用 OpenClaw,成本优化不必太复杂。先保证任务质量更重要。如果你已经把 OpenClaw 用在内容、运营、账号矩阵或自动化执行里,成本优化就应该成为工作流设计的一部分。
对 Jumei.ai 用户来说,建议把 Jumei.ai 当成执行环境,把 OpenClaw 当成 Agent 流程组织层。这样既能控制模型调用成本,也能把账号、设备、内容和复盘放进同一套业务链路里。

