
Key Takeaways
- 第一次跑通 Agent 任务,最重要的不是先追求复杂自动化,而是先把环境、权限和工具入口配对。
- 更适合第一批跑通的任务,是输入清楚、结果可检查、失败可恢复的任务。
- OpenClaw 真正容易出问题的地方,不在“能不能回答”,而在“能不能安全地执行”和“出错后能不能停住”。
- 对中文团队来说,先跑一个最小任务,再逐步放大,比一开始全链路接入更稳。
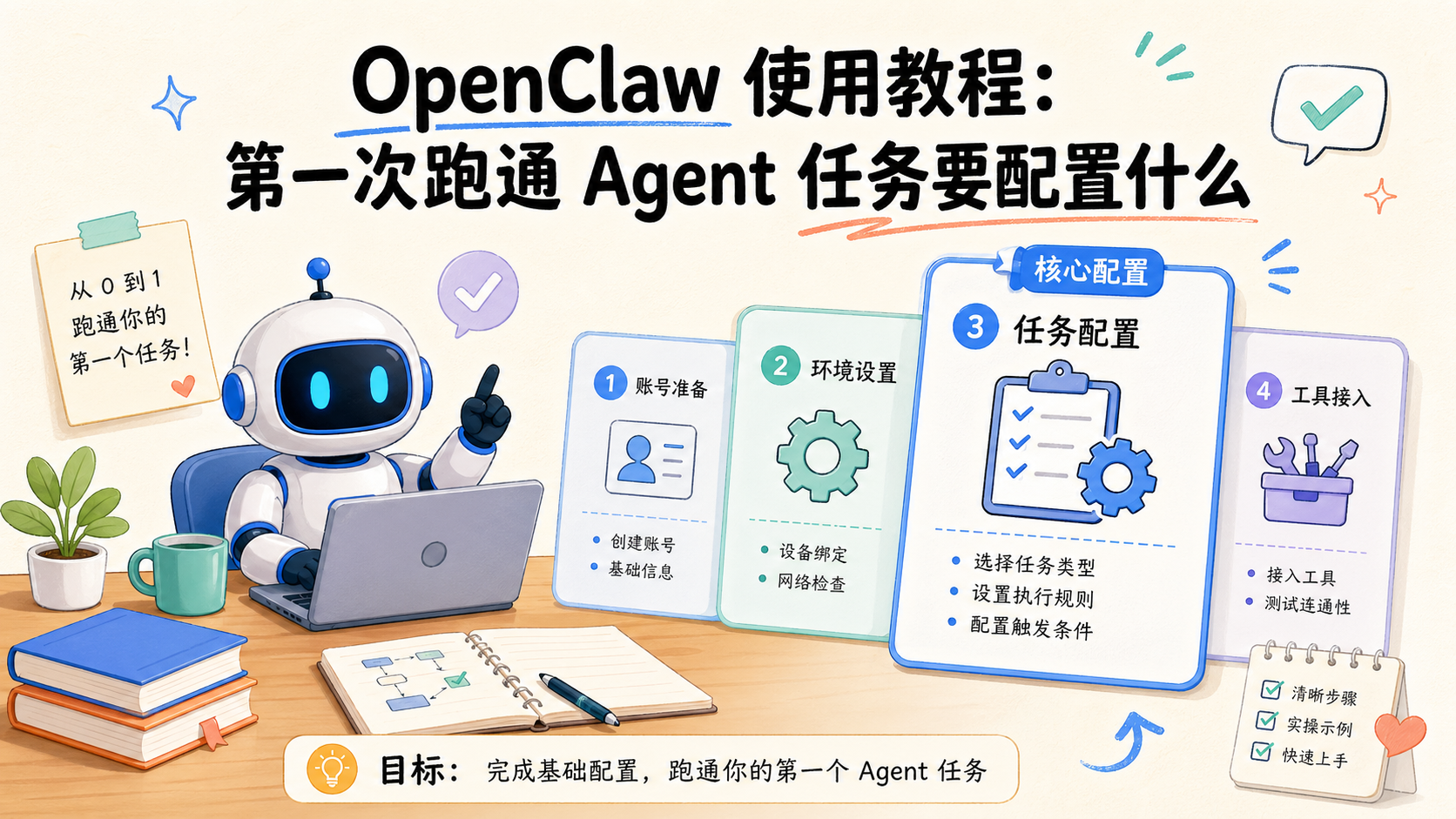
先给直接答案:第一次跑通 Agent 任务时,你最该先配置的是运行环境、权限边界、工具入口、任务目标和恢复路径,而不是先找一个最复杂的场景去演示。很多人第一次接触 OpenClaw,会把注意力放在模型、界面或一段看起来很聪明的演示上,但真正决定任务能不能稳定跑通的,通常是这些底层配置。
这篇 OpenClaw 使用教程要解决的,就是中文用户第一次上手时最容易混乱的部分。你到底要先准备哪些目录、哪些权限、哪些工具连接、哪些规则不能越过,什么任务适合先让 Agent 跑,什么任务不该第一天就交给它。只要这些地方没理顺,后面越接越多,失败成本就越高。
如果你要把 Agent 任务放到更真实的执行环境里理解,可以一起看 Jumei 首页、AI 指纹浏览器方向、移动端云控方向 和 社媒矩阵运营方向。如果你想看内容质量和搜索可用性的基础要求,也可以参考 Google Search Central 的 helpful content 指南、Model Context Protocol 介绍 和 OpenAI Agents SDK 文档。
OpenClaw 使用教程:先理解第一次跑通任务到底在跑什么
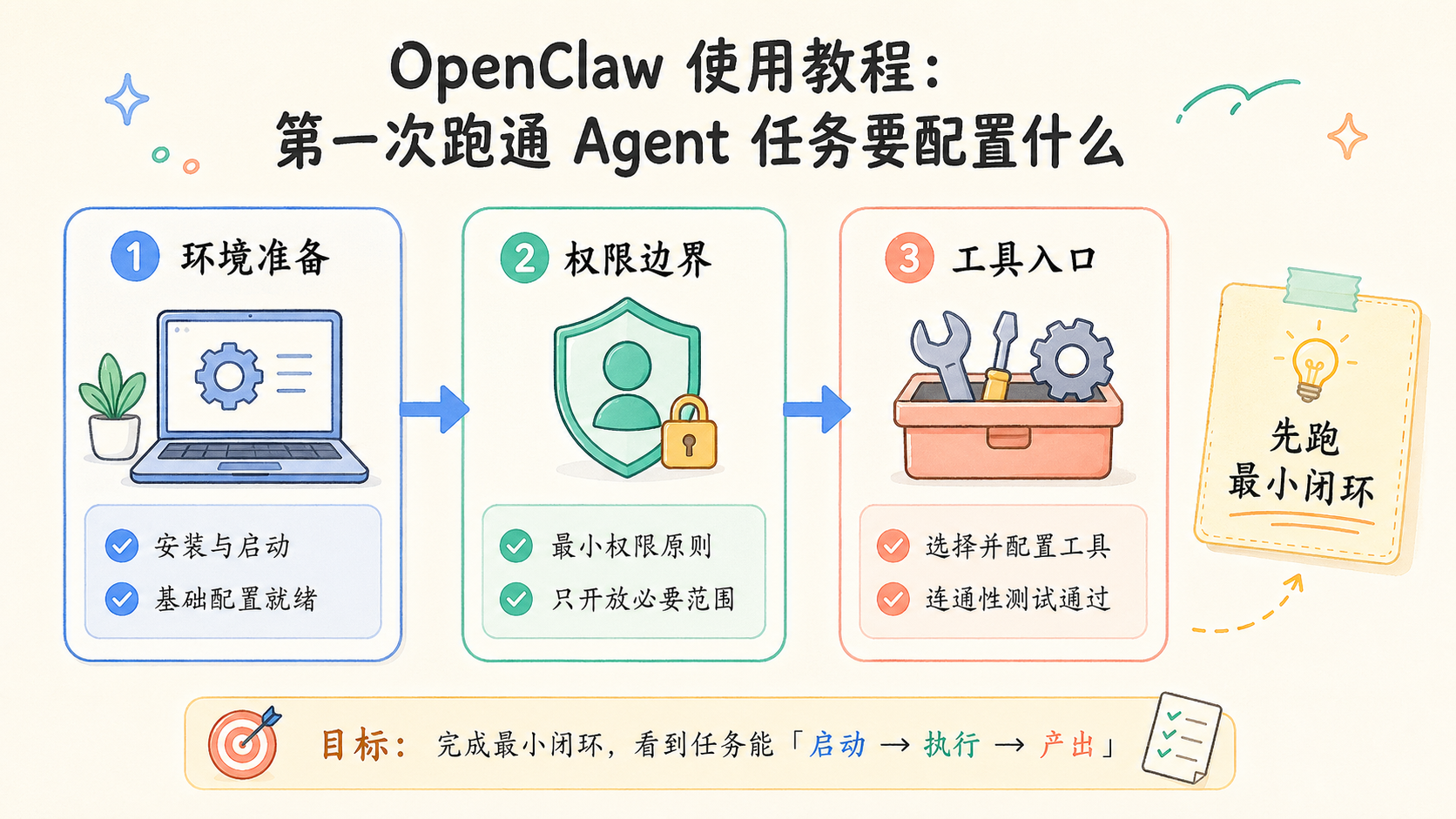
第一次跑通 Agent 任务,不是为了证明 Agent 很聪明,而是为了证明一条最小流程能在你的环境里稳定执行。这个目标一定要先分清。
很多中文用户第一次测试时,会直接给一个大任务,比如“帮我自动化整个流程”“帮我全自动跑完运营动作”。这种做法通常会把问题混在一起。你最后分不清是模型理解错了、权限不够、工具没接好,还是环境本身就不稳定。
更稳的理解方式,是把第一次跑通任务当成一次最小验证。你要验证的不是“它什么都能做”,而是“它能不能在限定边界里完成一个清楚动作”。例如读取一个文件、检查一个页面状态、整理一组资料、输出固定格式结果、回写一条日志。这类动作更适合用来确认配置是否配对。
所以第一次跑通任务,本质是在验证三件事。第一,Agent 是否理解任务。第二,工具是否真的接通。第三,出错时系统是否能停住并给出可修的反馈。只要这三件事能成立,你后面再扩大任务,成功率才会高。
OpenClaw 使用教程:第一次要先配置哪些环境
第一次配置时,环境比任务本身更重要。因为环境不稳,再简单的任务都会变得不可靠。
第一类是工作目录和文件路径。Agent 要读什么、写什么、能写到哪里、不能碰哪里,最好提前写清。第二类是运行时环境。你用哪个 Python、哪个依赖、哪个本地项目目录,这些信息如果含糊,第一次就容易卡在执行入口。第三类是目标资源环境。比如浏览器、文件资源、MCP 服务、移动端环境,哪些已经可用,哪些只是计划接入,也要分清。
第一次上手要先确认的环境项
| 环境项 | 先确认什么 | 如果没确认会怎样 |
|---|---|---|
| 工作目录 | Agent 在哪个项目里读写 | 文件路径错位,结果写丢 |
| 运行时 | 解释器、依赖、命令入口是否可用 | 任务根本跑不起来 |
| 资源入口 | 浏览器、文件、服务是否接通 | 动作只能停留在建议层 |
| 输出位置 | 结果要写到哪里、谁来接收 | 流程完成了却没人能接住 |
中文用户第一次配置时,最常见的问题不是少一个功能,而是少一个“确定的入口”。入口不确定,后面所有自动化都会发散。这也是为什么很多 OpenClaw 使用教程看起来步骤不多,真正落地时却容易卡住。
OpenClaw 使用教程:权限边界为什么要先配
很多人第一次上手,容易把“先跑通”理解成“先放开”。这恰好是最容易出问题的地方。
权限边界的作用,不是限制你,而是保证第一次试跑可控。哪些目录能写,哪些目录只能读;哪些命令允许自动执行,哪些动作必须人工确认;哪些外部资源可以接,哪些先不要碰。这些都属于第一次就该写清的边界。
如果没有权限边界,第一次跑通任务看起来可能成功,但你并不知道它到底有没有碰到不该碰的地方。对于需要处理账号、内容、批量动作或环境配置的团队来说,这个风险会更明显。
更稳的做法通常是先把权限分成三层。第一层是只读任务,第二层是低风险写入,第三层才是局部执行动作。第一次试跑尽量先停在前两层。这样即使任务失败,恢复成本也更低。
第一次跑什么任务最合适,什么任务别急着跑
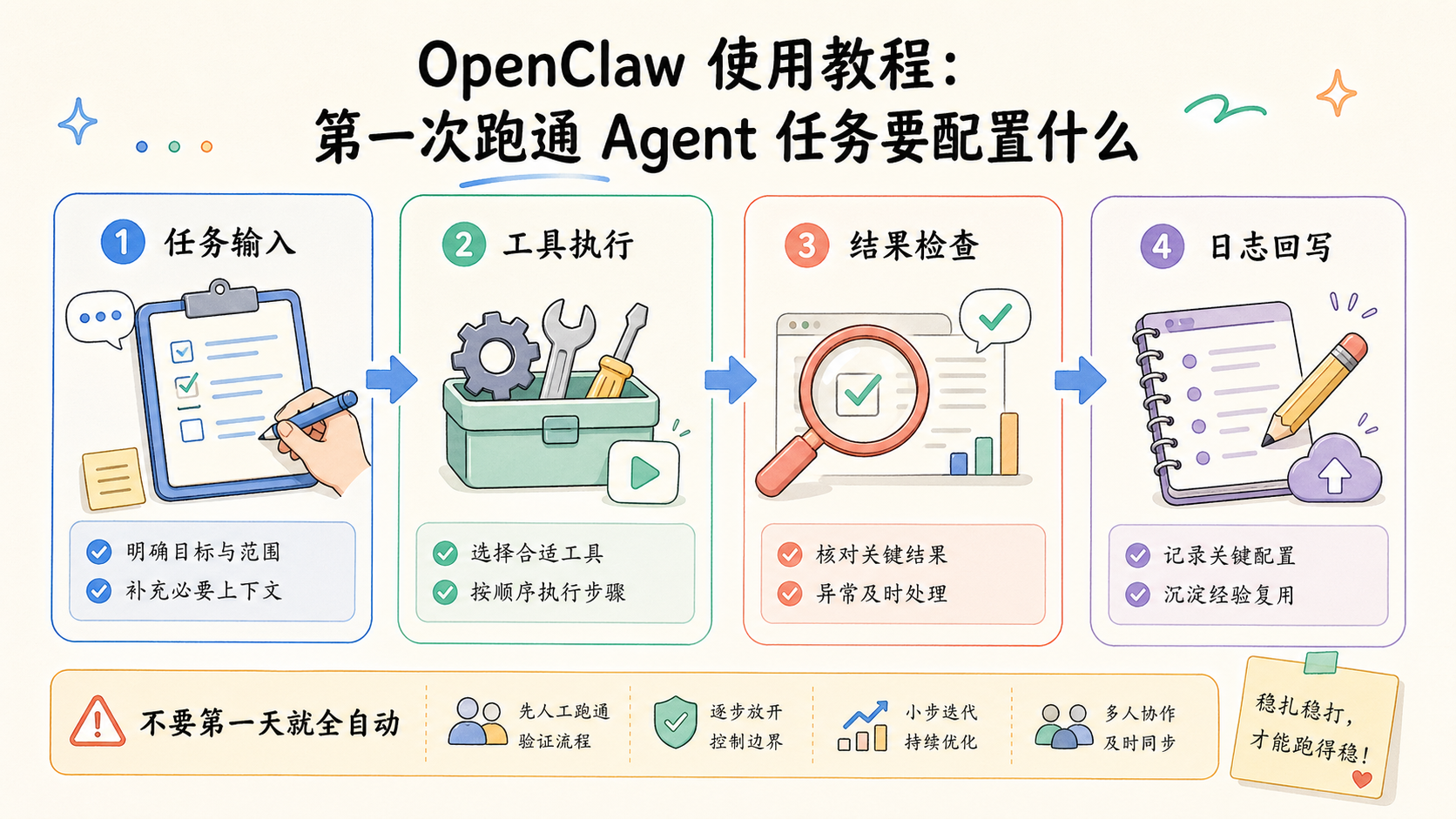
先给结论:第一次最适合跑的是小任务,不是大任务。
更适合作为第一批试跑的任务,通常有这些特征。输入清楚,输出清楚,中间步骤不多,结果可检查,失败能恢复。比如读取一组内容并按格式整理、检查一个页面的结构项、汇总一个目录内的资料、生成一份固定模板的报告、读取状态后回写日志。
不适合作为第一次试跑的任务,也很明确。涉及高权限账号操作、批量发布、不可逆删除、复杂业务判断、多系统级联写入的任务,都不适合第一天就拿来验证。
适合第一次试跑
- 读取并整理资料
- 检查页面或文件状态
- 生成固定格式结果
- 回写一条低风险记录
不适合第一次试跑
- 批量发布
- 敏感权限改动
- 不可逆删除
- 强依赖人工判断的复杂决策
很多 OpenClaw 教程看起来会让人觉得“越完整越好”。但对第一次试跑来说,范围越小,越容易看清问题。真正有效的 OpenClaw 使用教程,重点通常不是堆功能,而是先把第一个最小闭环跑稳。
OpenClaw 使用教程:工具入口应该怎么接
第一次接工具,不建议一口气全接。更稳的路线通常是按任务顺序来接。
如果你的任务是“读取信息、整理结果、写回文件”,那第一次就先接文件入口。不要同时再接浏览器、图片和多个外部服务。先把一条最小链路跑通,你更容易知道问题出在哪。
如果你的任务要用浏览器,也建议先做只读动作,比如打开页面、定位信息、检查状态,而不是一上来就做复杂点击和提交。对做社媒执行、账号管理或多环境协同的团队来说,这个顺序尤其重要。因为网页端和移动端环境一旦都接进来,排错成本会明显上升。
可以把第一次接工具理解成三步:
- 先接一个最核心入口。
- 再确认结果能被正确读取或写回。
- 最后才补充第二个和第三个入口。
这个顺序听起来慢,但更适合真正要落地的团队。因为你是在做可复用流程,不是在做一次性演示。
OpenClaw 自动化第一次为什么常常卡住
OpenClaw 自动化第一次卡住,通常不是因为“AI 不够聪明”,而是因为几个基础条件没同时成立。
最常见的卡点有四个。第一,任务目标写得太大。第二,权限没有提前收好。第三,工具入口不清楚。第四,结果没有人能检查。只要命中其中两个,第一次试跑就很容易变成一团乱。
还有一个容易被忽略的问题,是恢复路径没写。任务失败后,是直接重跑,还是先清理状态,再补一个输入,再重新执行,很多人第一次都没有预案。结果就是一旦失败,只能人工救火。
所以第一次 OpenClaw 自动化试跑,真正的成功标准不是“看起来很顺”,而是“即使失败也知道下一步怎么办”。
更稳的第一次试跑顺序是什么
如果你想要一个更实用的做法,可以按这个顺序来:
推荐试跑顺序
- 先选一个最小任务,不要跨太多系统。
- 写清输入、输出、禁用动作和检查标准。
- 先接一个核心工具入口,不要同时全接。
- 让 Agent 只跑一次最小闭环。
- 记录失败点和恢复动作,再决定要不要扩大。
这个顺序的价值,在于它能帮助你把“配置问题”和“任务问题”分开。只要能分开,后续修复会轻很多。
常见问题
OpenClaw 是什么,为什么第一次试跑前要做这么多配置?
OpenClaw 可以理解成把 Agent 任务接到真实工具和执行入口上的工作方式。第一次要做这些配置,是因为它不只是聊天,还可能读取文件、调用工具、接触真实环境。
OpenClaw 使用教程里最容易被忽略的点是什么?
最容易被忽略的是权限边界和恢复路径。很多人只看怎么跑起来,不看出错后怎么停下来。
第一次跑通 Agent 任务,应该先追求什么?
应该先追求可控和可复盘,而不是复杂和华丽。能稳定完成一个最小任务,比勉强跑一个大任务更有价值。
OpenClaw 安装好以后就能直接自动化吗?
通常不能这么理解。安装只是开始,真正能不能自动化,要看环境、权限、工具入口和任务边界有没有一起配好。
哪些任务最适合做第一次 OpenClaw 自动化?
资料整理、状态检查、固定格式输出、低风险回写这类任务最适合。因为它们更容易验证,也更容易恢复。
如果我要做海外社媒矩阵运营,第一次应该接哪些环境?
建议先从最贴近当前流程的一个入口开始,比如先理解 Jumei.ai 的整体执行环境,再根据任务只接网页端或移动端中的一边,不要一次全接。
第一次试跑成功以后,下一步做什么?
下一步不是立刻放量,而是先复盘:哪里成功,哪里失败,哪些规则该写进长期配置,哪些动作仍然要人工确认。
OpenClaw 教程为什么总强调“小任务先跑”?
因为小任务更容易暴露真实问题。第一次就跑大任务,往往只会把多个问题叠在一起,让你更难判断到底哪里没配好。
总结

这篇 OpenClaw 使用教程的核心结论很简单:第一次跑通 Agent 任务时,先配环境、权限、工具入口、任务边界和恢复路径,再去追求更复杂的自动化。顺序对了,后面扩大才稳;顺序错了,再强的模型也会被混乱配置拖住。
对中文团队来说,最值得追求的不是“第一天就全自动”,而是“第一天就把最小闭环跑得可控、可复盘、可继续扩展”。这才是第一次真正跑通 Agent 任务的意义。

