
Key Takeaways
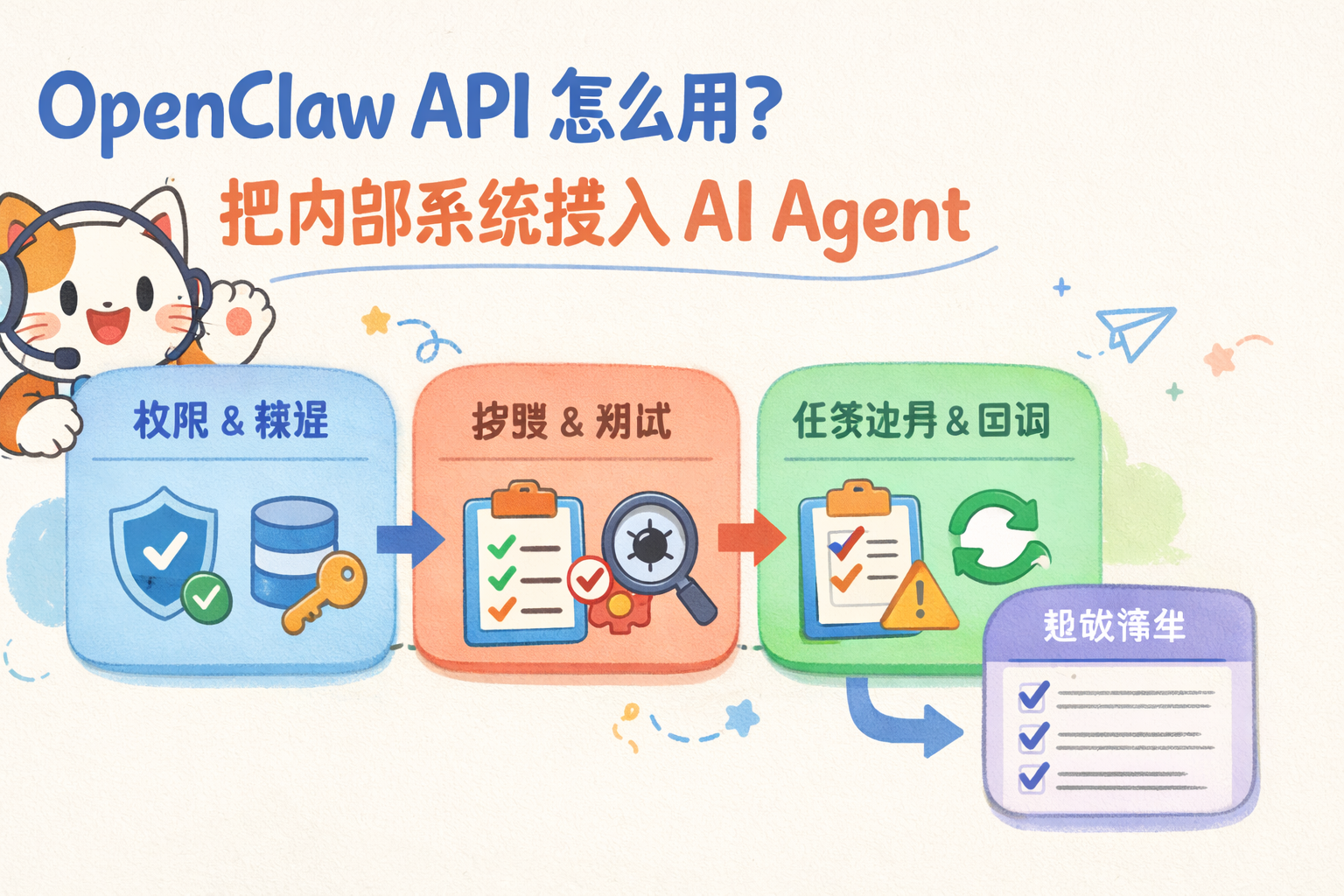
- OpenClaw API 的核心用途,是把内部系统里的任务、数据和权限接入 AI Agent,让 Agent 能在边界内执行和回写。
- 接入前要先定义任务输入、允许动作、输出格式、失败处理和人工审核点,不要直接把生产系统交给 Agent。
- 最稳的做法是先跑低风险试点,用日志、回调、错误分类和验收清单确认流程可控,再扩大到更复杂业务。
OpenClaw API 怎么用?简单说,就是让内部系统通过 API 把任务交给 AI Agent,并接收执行结果、状态变化和异常信息。它不是单纯“调一个接口”,而是把企业已有系统、业务流程和 Agent 执行层连起来。
适合接入的场景,通常有明确任务边界。例如从 CRM 读取待跟进线索,让 Agent 生成初步分类;从运营后台取任务列表,让 Agent 给出下一步建议;从内容系统读取素材,让 Agent 做检查和标记。如果任务目标不清、权限边界不清、结果无法验收,先不要急着接 API。
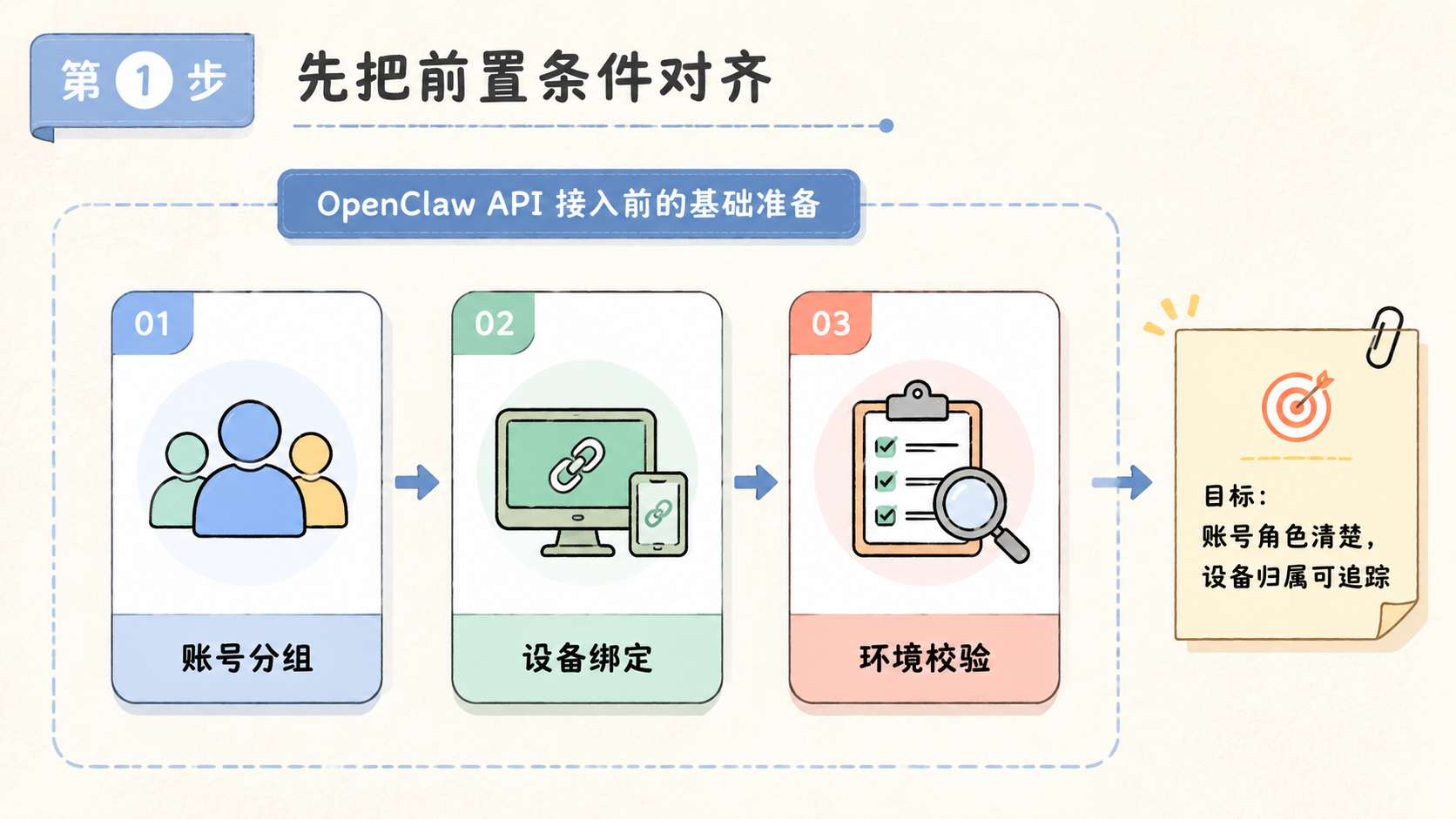
先把前置条件对齐 and OpenClaw API
接 OpenClaw API 前,先对齐四件事:系统入口、任务边界、权限范围和回写规则。没有这些前置条件,接口能调通也不代表业务能跑通。
系统入口指内部系统准备从哪里触发任务。可能是后台按钮、定时任务、消息队列,也可能是运营人员在看板里勾选任务。入口越清楚,越容易记录谁触发了任务、触发了什么任务、任务跑到哪一步。
任务边界指 Agent 能做什么、不能做什么。比如只能读取客户备注,不能修改客户状态;只能生成回复建议,不能直接发送消息;只能整理账号数据,不能批量修改账号资料。这些边界要写成规则,不要只靠口头约定。
权限范围要分级。读取数据、生成建议、写入标签、触发外部动作,风险等级不同。建议先从只读和建议类任务开始,再逐步放开回写能力。
如果接入场景和社媒矩阵运营有关,可以先看 工作方式 的流程思路,把任务从人肉沟通变成可追踪步骤。API 接入只是技术入口,流程设计才是重点。
OpenClaw API 怎么用?把内部系统接入 AI Agent 的操作步骤
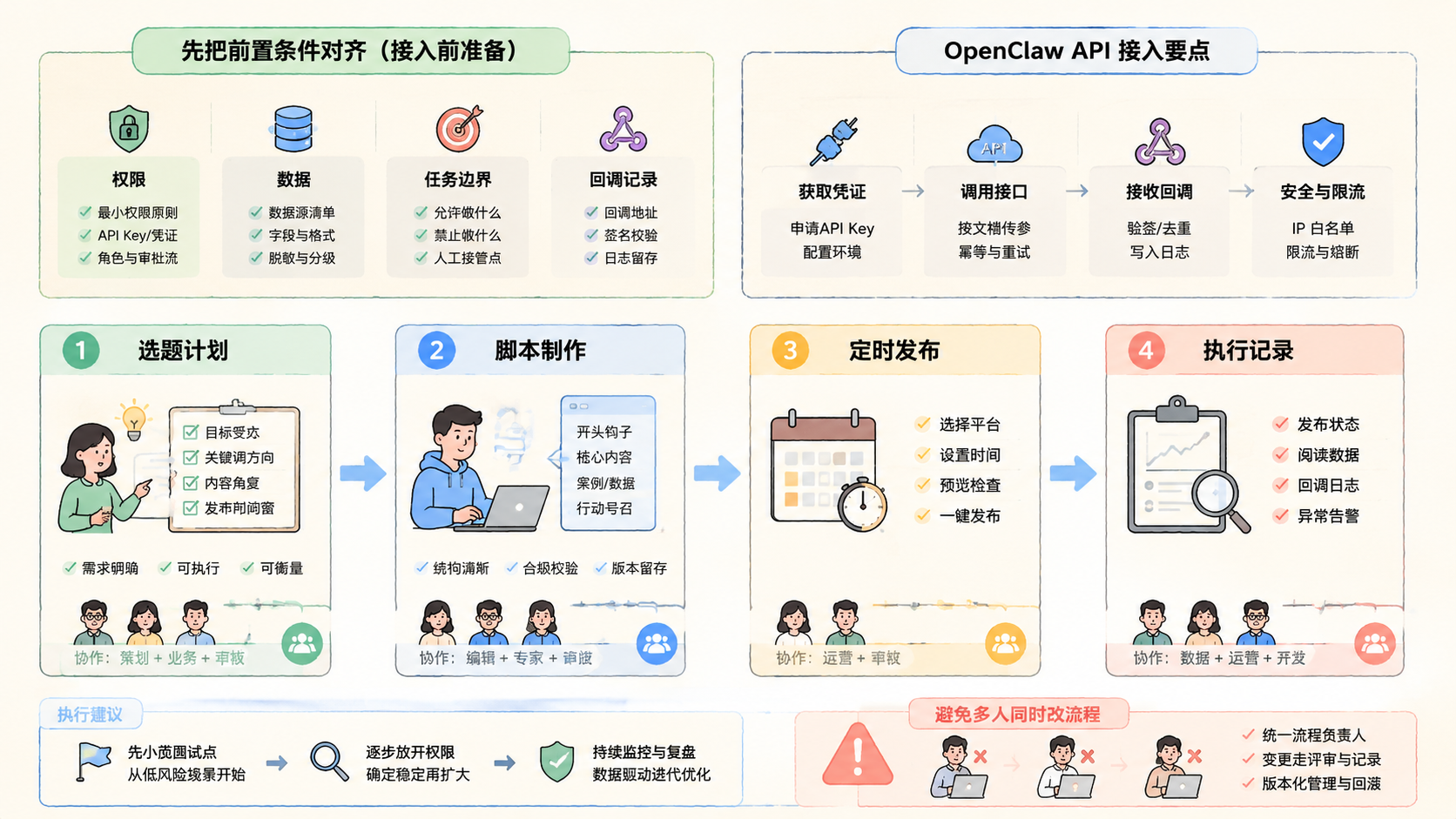
实际操作可以分成 7 步。先从低风险流程开始,不要一上来接核心生产动作。
- 选定一个任务:选择重复、边界清楚、结果可检查的任务。
- 定义输入字段:明确内部系统传给 Agent 的字段,比如任务 ID、账号、场景、文本、附件、截止时间。
- 定义允许动作:写清楚 Agent 只能读取、分析、标记、建议,还是可以回写系统。
- 设计输出格式:输出要能被系统解析,比如状态、分类、建议、异常原因、下一步动作。
- 配置回调记录:内部系统要能接收任务状态,包括已创建、执行中、完成、失败、需要人工确认。
- 设置人工审核点:高风险动作必须先进入待审核状态。
- 做小范围试运行:先跑 20 到 50 条样本,再决定是否扩大。
这里不要编造“万能参数”。不同团队内部系统不同,API 字段也会不同。更稳的做法,是先画出任务流,再决定字段。
一个常见的任务流是:内部系统创建任务,OpenClaw API 接收任务,AI Agent 执行分析,系统收到结果,人工审核高风险建议,最后把状态回写到业务表。每一步都要有日志。
如果团队已经有 自动化运营 的需求,可以把 API 接入放在重复任务上。例如自动整理待处理线索、标记异常内容、生成运营复盘草稿。不要先接删除、批量发送、修改账号设置这类高风险动作。
中间最容易出错的地方
最容易出错的地方,是把 OpenClaw API 当成普通接口,而不是业务流程的一部分。接口返回成功,只说明技术调用完成,不说明任务完成得正确。
常见错误包括:
- 输入字段太少:Agent 拿不到任务背景,只能猜。
- 输出格式太自由:内部系统无法稳定解析结果。
- 权限边界太大:试点期就允许高风险回写。
- 没有错误分类:失败后只看到失败,不知道原因。
- 没有人工审核:Agent 建议直接进入生产动作。
- 没有回滚方案:出错后无法恢复旧流程。
排查时先看日志链路。任务是否创建成功,字段是否完整,Agent 是否收到正确上下文,输出是否符合格式,内部系统是否正确回写。不要只看最后一步。
Google Cloud 关于 迁移评估和工作负载发现 的思路适合参考:先理解工作负载,再决定迁移或接入方式。API 接入也是一样,先理解任务,再接入 Agent。
OpenClaw API 如何确认操作结果
确认 OpenClaw API 接入是否成功,不只看接口状态码。要看业务闭环是否完成。
可以用下面的验收表:
| 验收项 | 通过信号 | 需要修复的信号 |
|---|---|---|
| 输入完整 | 每个任务都有 ID、场景、字段和权限 | Agent 经常缺背景 |
| 输出稳定 | 系统能解析状态、分类和建议 | 输出格式经常变化 |
| 错误可查 | 失败能归类到字段、权限、流程或模型 | 只能看到失败 |
| 人工审核 | 高风险动作进入待确认 | Agent 直接改生产数据 |
| 回滚能力 | 可以暂停 API 并恢复旧流程 | 一停接口业务就中断 |
OpenAI 的 Agent evals 文档 强调用评测观察 Agent 任务表现。接入 OpenClaw API 时,也应该把任务样本固定下来,反复测试正常样本、异常样本和边界样本。这样才能知道流程是否稳定。
如果验收只看“接口通了”,风险很大。真正的验收要看:任务是否能被追踪,结果是否能被理解,失败是否能被复盘,人工是否能接管。
下一步还能怎么优化
接口跑通后,不要马上扩大到全部业务。下一步应该优化任务质量和复盘链路。
可以从三处优化。第一,优化输入字段,让 Agent 拿到足够上下文。第二,优化输出格式,让内部系统更容易处理结果。第三,优化失败分类,让团队知道问题来自数据、权限、规则还是任务本身。
如果接入的是社媒账号或获客流程,可以结合 多账号管理 和 获客引流 的流程,把账号、线索和任务关联起来。比如每条线索都记录来源账号、内容、处理建议和人工审核结果。
Google Search Central 的 helpful content 文档 提醒内容要服务真实用户。放到内部系统接入里,也可以理解为:Agent 输出要服务真实业务动作,而不是只生成看起来完整的文本。
适合谁,不适合谁
OpenClaw API 更适合已经有内部系统、明确任务流和基本技术维护能力的团队。它不是给没有流程的团队直接“自动变强”的工具。
更适合的团队:
- 已经有 CRM、内容系统、运营看板或数据后台。
- 有重复任务需要交给 AI Agent 处理。
- 能定义输入字段、输出格式和验收标准。
- 有人负责日志、错误排查和权限管理。
暂时不适合的团队:
- 业务流程还靠聊天记录和人工记忆。
- 不知道 Agent 应该完成什么任务。
- 没有技术人员维护 API 和日志。
- 希望一接入就自动处理所有复杂问题。
如果团队还处在流程梳理阶段,可以先用低代码表格或任务看板跑通 SOP。等任务边界稳定后,再接 OpenClaw API 更稳。
试运行、验证与复盘
试运行建议控制范围。不要把所有内部系统一次性接入 AI Agent。
一个可执行的试运行方案是:选 1 个系统、1 个任务类型、20 到 50 条样本、2 周周期。每条任务记录输入、输出、执行时间、人工介入原因和业务结果。试运行结束后,按任务完成率、人工修改率、失败可解释率和业务使用率复盘。
如果失败可解释率很低,说明日志和输出格式还不够。先补记录,不要扩大。如果人工修改率很高,说明任务定义或输入字段不够清楚。先修任务,不要怪 Agent。
复盘结论要具体。比如“继续扩大到线索分类”,“暂停自动回写客户状态”,“补充账号字段”,“增加人工审核”。只有结论能指导下一步,试运行才有价值。
常见问题
OpenClaw API 是什么?
可以理解为内部系统和 AI Agent 之间的接口层。内部系统通过它提交任务、传递上下文、接收结果和记录状态。具体字段要按业务流程设计。
OpenClaw API 怎么用才安全?
先从只读和建议类任务开始。高风险动作要设置人工审核。所有任务都要有日志、状态和失败原因,不要直接让 Agent 修改核心数据。
需要先安装 OpenClaw 吗?
如果团队使用的是自有部署或指定运行环境,通常要先完成安装、权限和网络配置。具体安装方式要以实际部署文档为准,不要在没有环境信息时照搬教程。
内部系统接入 AI Agent 最难的地方是什么?
最难的通常不是接口调用,而是任务边界。系统要知道传什么,Agent 要知道做什么,业务人员要知道怎么验收。三者缺一项,流程就容易断。
可以直接接生产系统吗?
不建议。先接测试环境或低风险流程。确认日志、权限、回调和人工审核都稳定后,再逐步扩大到生产流程。
失败后怎么排查?
先看任务输入是否完整,再看权限是否足够,然后看 Agent 输出是否符合格式,最后看内部系统回写是否成功。不要只看最后一个错误提示。
和普通自动化脚本有什么区别?
普通脚本更适合固定规则。OpenClaw API 接入 AI Agent 后,更适合处理需要文本理解、分类、建议和复盘的任务。但越灵活,越需要边界和审核。
下一步应该做什么?
先选一个低风险任务,写清输入字段、输出格式、权限范围和验收标准。跑完小样本后,再决定是否扩大到更多系统。
总结
OpenClaw API 的价值,不是把内部系统简单接到一个新工具上,而是让任务、数据、权限和 AI Agent 执行形成可追踪闭环。
真正可落地的接入,应该从小任务开始。先定义边界,再接接口;先做日志,再做自动化;先验收结果,再扩大范围。这样才能让内部系统接入 AI Agent 后变得更清楚,而不是更难排查。

