

Grok 接入 OpenClaw 的核心不是“省一笔 API 费用”这么简单,而是把 X Premium 账号里的模型能力、图片/视频能力和 X Search 能力,放进一个可调用、可审计、可接入任务系统的 Agent 工作流里。
原文的价值在于它把一次真实踩坑过程拆成了可复用步骤:环境检查、安装 CLI、xAI OAuth 授权、设置默认模型、启动 Gateway、配置 token、批准设备、验证模型调用、再把它接入定时任务。对运营团队来说,这比单纯在网页里使用 Grok 更接近生产流程。
Key Takeaways
- Grok 接入 OpenClaw 后,可以把 X Premium 配额变成 Agent 可调用能力。
- 第一版重点不是炫技,而是把 OAuth、Gateway、Token、设备批准和验证记录跑通。
- Grok X Search 适合做定时监控、账号动态收集、舆情扫描和内容选题。
- 对团队而言,必须把账号、权限、设备、任务和失败恢复放进统一流程。
- 如果要接入 云控系统 或矩阵运营流程,最重要的是记录谁授权、谁调用、谁审核。
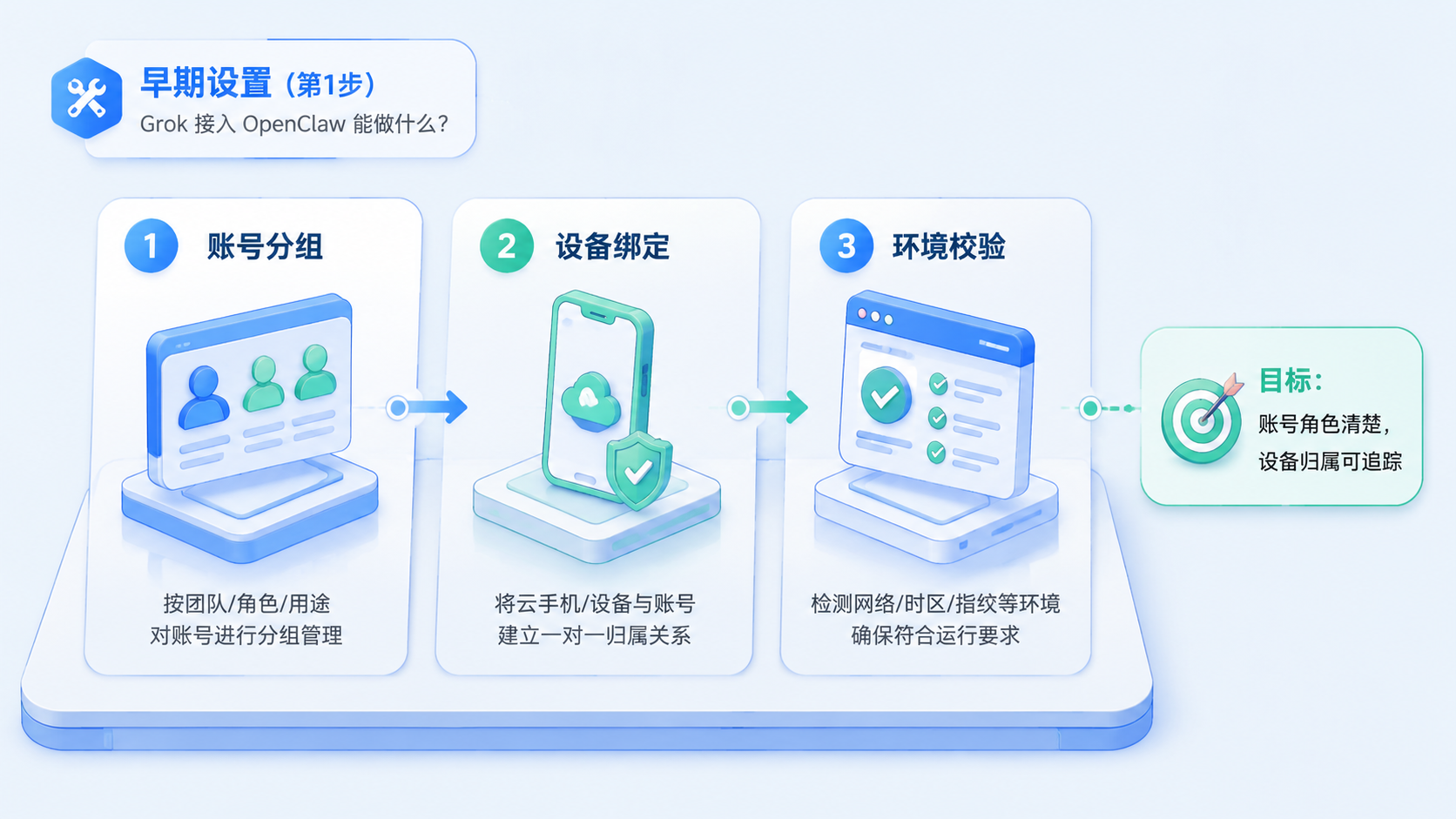
Grok 接入 OpenClaw 到底能做什么
Grok 接入 OpenClaw 后,原本只能在 X 或 Grok 页面里手动使用的能力,会变成 Agent 可以调度的模型能力。它不是简单把网页打开,而是通过 OAuth 授权和 Gateway 连接,把 Grok 放进命令行、工作流和自动化任务里。
这件事最直接的价值有三类。
第一,X Premium 订阅配额不再只用于聊天。账号本身的 Grok 能力可以进入 Agent 任务流,减少团队为了临时实验再单独配置一套 API Key 的负担。
第二,Grok Image 或视频生成能力可以进入内容生产链路。对内容团队来说,这意味着 Agent 可以根据任务生成图片、视频草稿或创意素材,再交给人工复核。
第三,Grok X Search 可以变成自动监控能力。比如每小时扫描指定博主、关键词、产品名或竞品动态,有新内容后推送给运营人员。
Grok 接入 OpenClaw 为什么适合矩阵团队
单人使用 Grok 时,打开网页、输入问题、复制结果就够了。但矩阵团队的问题不是“能不能问”,而是“谁在问、用哪个账号问、结果给谁、失败后谁处理”。
如果团队有多个运营账号、多个内容账号、多个监控对象和多个执行任务,就不能只靠个人浏览器状态。更好的方式是把 Grok 能力放到任务系统里,让任务记录包含账号来源、授权状态、模型版本、输入内容、输出结果和审核人。
这也是 矩阵系统 要关注的地方。AI 能力接进来以后,不应该变成一个没人管的黑盒工具,而应该进入账号空间、内容库、任务队列和审核节点。
对 jumei 这类多账号运营场景来说,Grok 接入 OpenClaw 更像是“模型能力接入层”。它可以服务选题监控、热点摘要、内容草稿、素材生成、账号复盘和竞品观察,但公开动作仍然要走审核。
前置条件:先把环境和账号边界确认清楚
原文给出的前置条件很直接:Node.js 24、可用的 X Premium 或 Premium+ 订阅、能够正常打开 accounts.x.ai。这三个条件看似基础,但它们决定了后面的授权和模型调用能不能顺利完成。
环境检查建议分成三步。
| 检查项 | 为什么重要 |
|---|---|
| Node.js / npm | OpenClaw CLI 和相关命令需要运行环境 |
| X Premium 账号 | Grok 能力来自账号授权和订阅配额 |
| accounts.x.ai | OAuth 授权必须能正常打开和返回 |
这里不要把账号密码直接交给脚本,也不要把所有人共用一个浏览器登录态。团队版应该明确账号负责人、授权人和调用范围。
Grok 接入 OpenClaw 第一步:环境检查
第一步是检查 Node.js 和 npm 是否可用。命令可以很简单:
node -v
npm -v
如果没有 Node.js,可以先安装 nvm,再安装 Node.js。原文使用的是 nvm-sh/nvm 的安装脚本,这类脚本在执行前要确认来源和版本,团队环境中更建议由管理员统一配置。
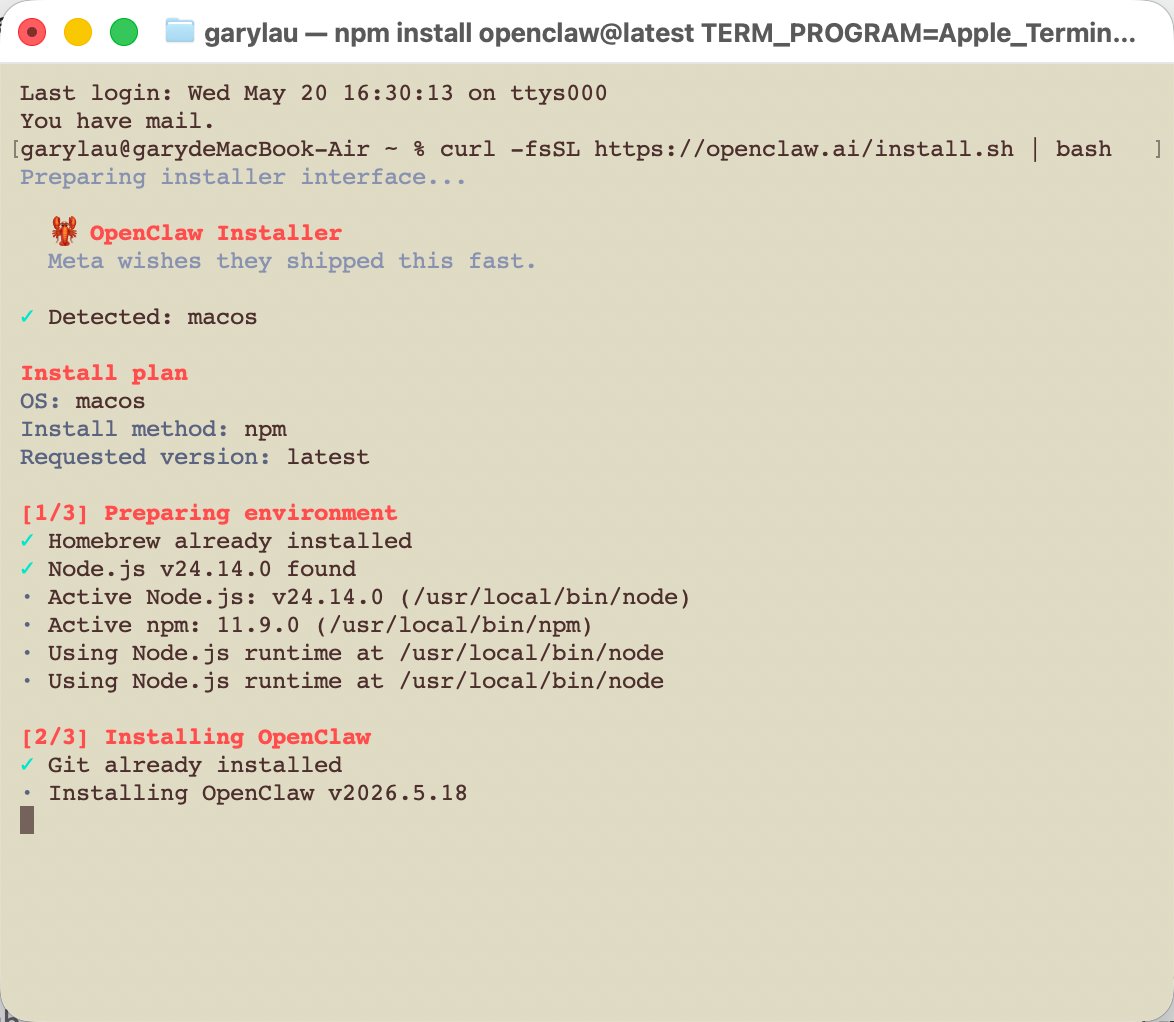
环境检查的意义不只是“能不能运行”。它还会影响后续 CLI 安装、Gateway 启动、日志路径和后台服务管理。如果多人协作,建议把版本写进团队文档,避免每个人本机版本不同导致问题难复现。
Grok 接入 OpenClaw 第二步:安装并验证
安装 OpenClaw 后,要马上做一次版本验证。可以参考 OpenClaw Getting Started 对安装、初始化和 Gateway 的说明。不要等到授权失败、Gateway 起不来时,才回头排查安装是否完整。

团队落地时,建议把安装验证拆成三类记录:
- CLI 是否存在。
- 版本是否符合当前流程。
- 日志目录是否可访问。
- 当前用户是否有执行权限。
这一步看起来偏工程,但对自动化运营很关键。因为后面每个 Agent 调用失败,都可能和 CLI、Gateway、授权、网络、模型状态有关。没有基础记录,排查会变成猜谜。
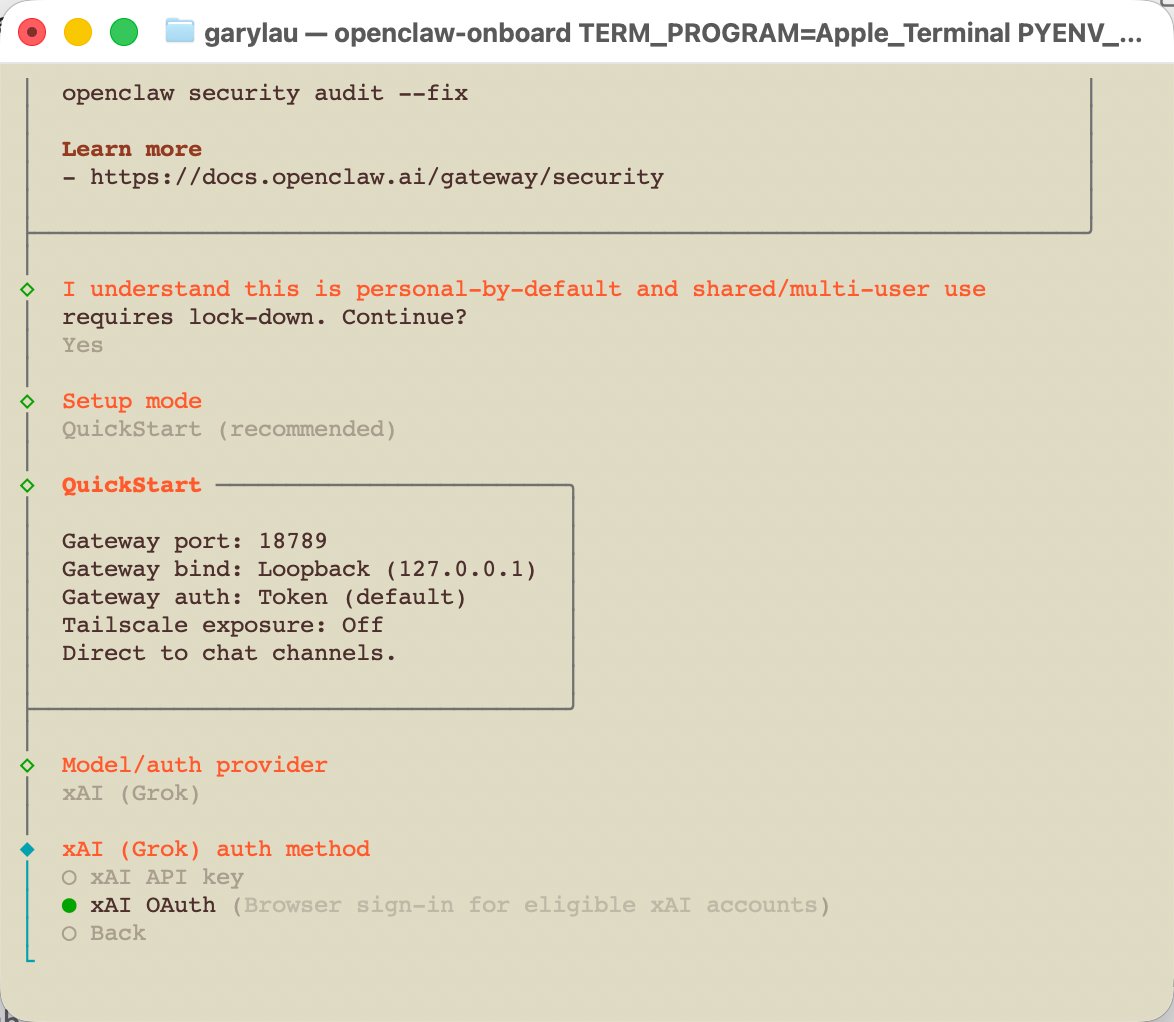
Grok 接入 OpenClaw 第三步:初始化并完成 xAI OAuth 授权
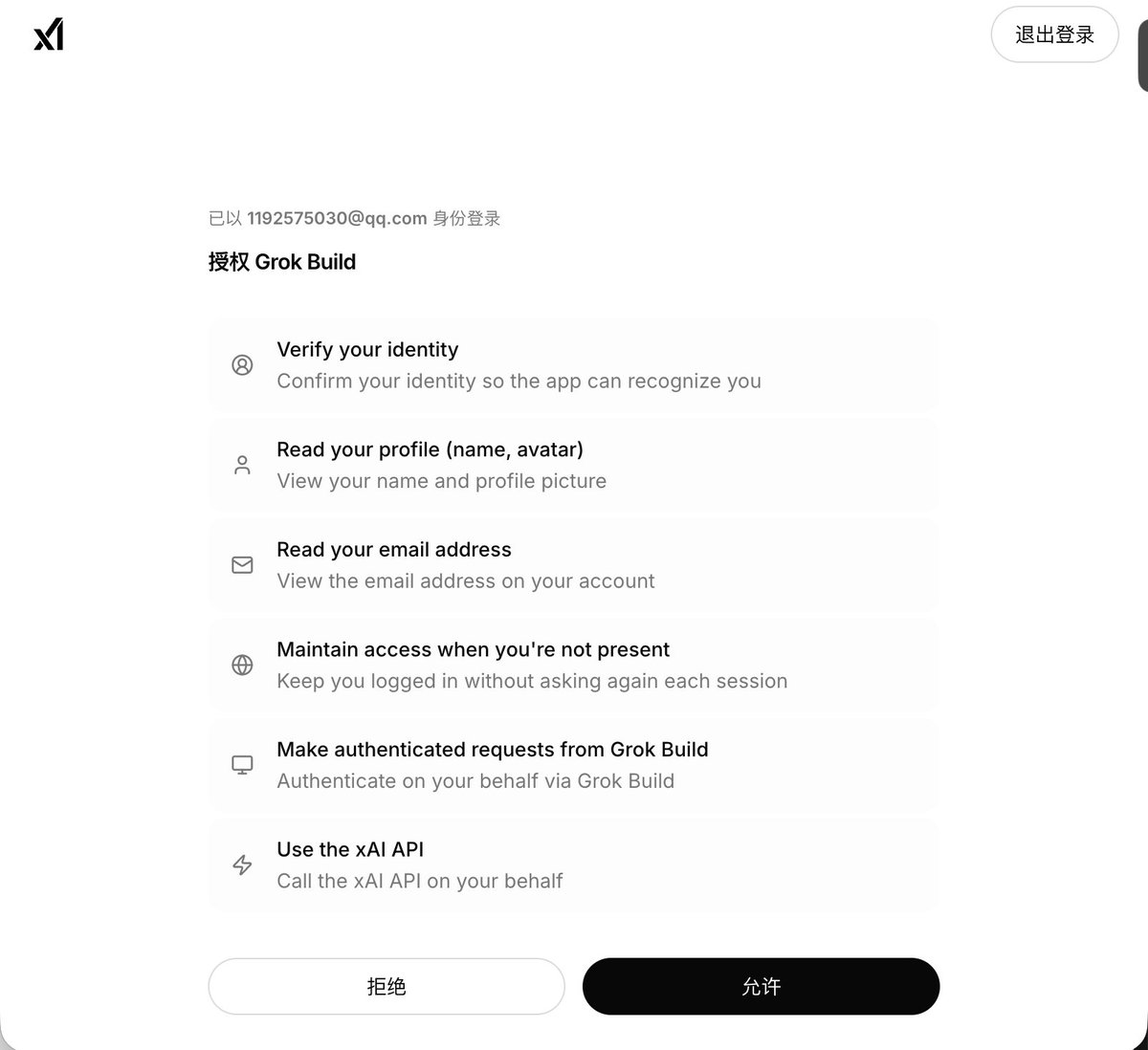
真正的关键步骤是初始化并选择 xAI / Grok 授权。原文里的思路是进入配置向导,选择本地 Gateway、模型配置、xAI 作为模型提供方,并选择 xAI OAuth 授权方式。
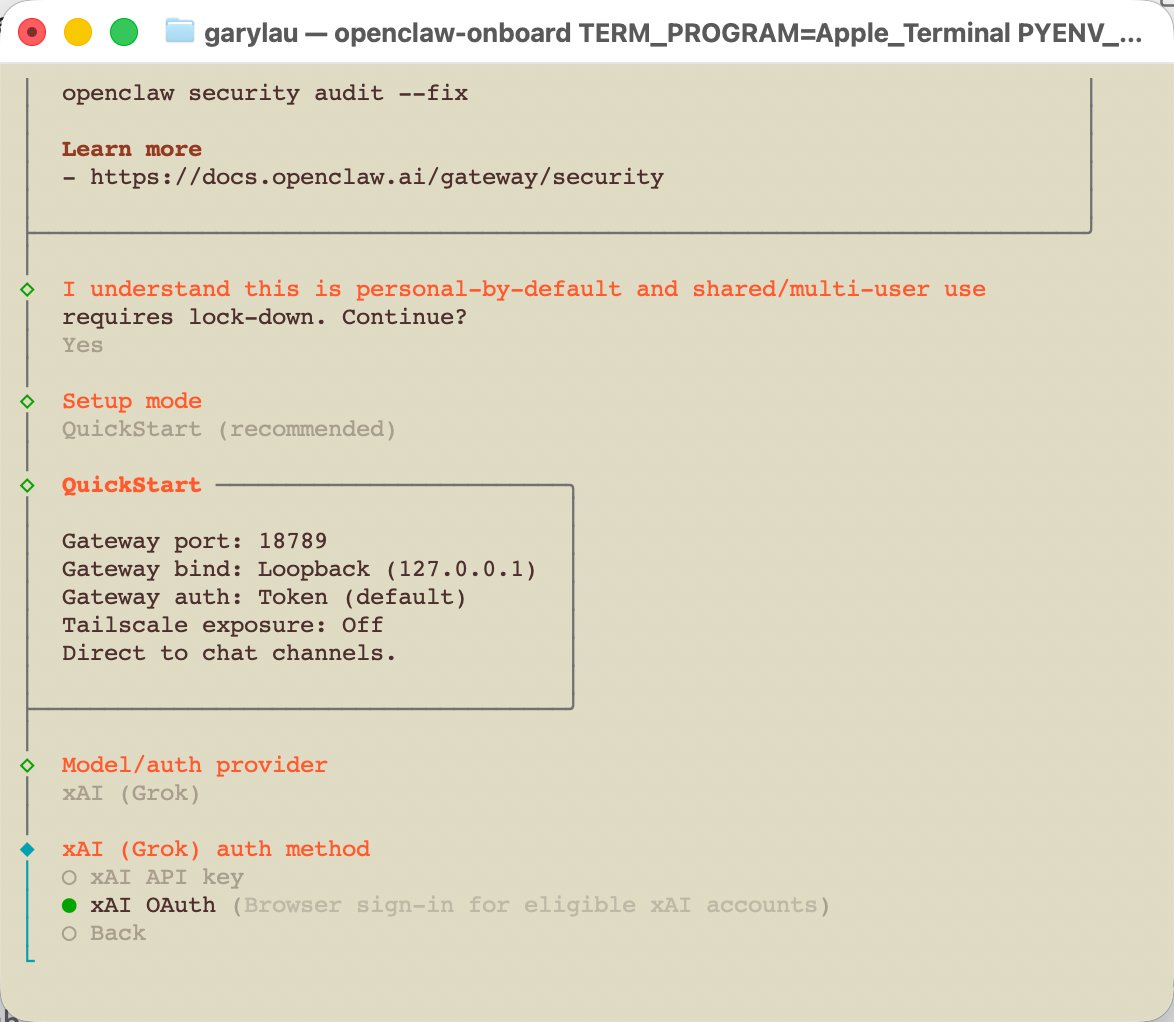
OAuth 的好处是边界清楚。账号所有者授权,系统拿到可用凭证,再由 Gateway 对外提供受控访问。xAI 的官方文档说明了 Grok 在 Web、X 应用和 API 等入口中的可用形态,具体额度和访问方式仍以 xAI Docs 与账号实际状态为准。
但这里也要注意,OAuth 不是“无限权限”。团队要记录授权账号、授权时间、使用范围、调用人、失效时间和异常处理方式。否则一旦多人共用,就很难知道是哪条任务消耗了配额。
第四步:设置 Grok 默认模型
授权完成后,需要确认有哪些 Grok 模型可用,再设置默认模型。原文提到的思路是列出 xai/ 开头的模型,然后把常用模型设成默认模型。

对个人使用来说,默认模型只是省事。对团队来说,默认模型会影响成本、速度、能力和输出稳定性。
建议至少记录这些字段:
| 字段 | 示例 |
|---|---|
| 默认模型 | xai/grok-4.3 |
| 备用模型 | xai/grok-code-fast-1 |
| 调用入口 | CLI / Gateway / 工作流节点 |
| 适用任务 | 搜索、摘要、图片理解、代码辅助 |
| 失败处理 | 降级、重试、转人工 |
如果团队把 Grok 接入 自动化运营,默认模型不应该由某个运营随手改,而应该进入配置管理。需要调用 xAI API 的场景,也可以参考 xAI API 的官方说明来区分订阅入口和 API 入口。
第五步:启动 Gateway 并设置 Token
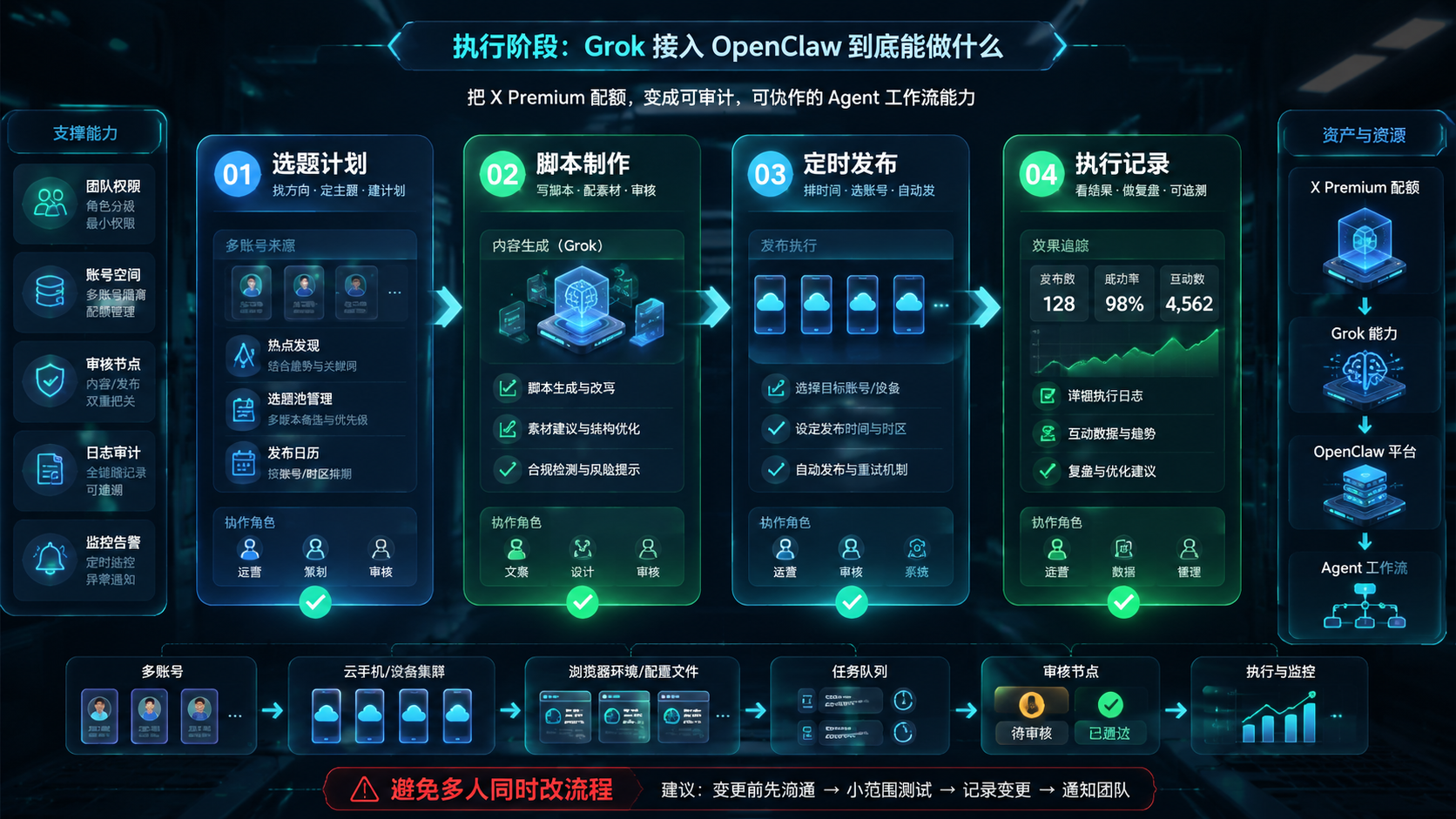
Gateway 是把本地模型能力暴露给 CLI、Agent 或工作流调用的关键层。原文里有两种思路:安装成后台服务,或者临时运行。
个人测试可以临时跑。团队环境更建议使用后台服务,并明确端口、Token、日志、启动命令和重启方式。
Token 配置尤其重要。不要把 Token 写在公开文档或群聊里,也不要所有任务共用一个无法追踪的 Token。更好的方式是把 Token 放入受控配置,并把调用任务记录到系统里。
如果要把 Gateway 接进 工作方式 或自有任务编排,建议把它视为一个受控工具,而不是随便开放的本地服务。
第六步:批准设备和处理 scope upgrade
原文里提到,如果页面提示需要批准设备,就通过设备列表找到 pending 请求并批准。发消息时如果遇到 scope upgrade,也按同样方式处理。
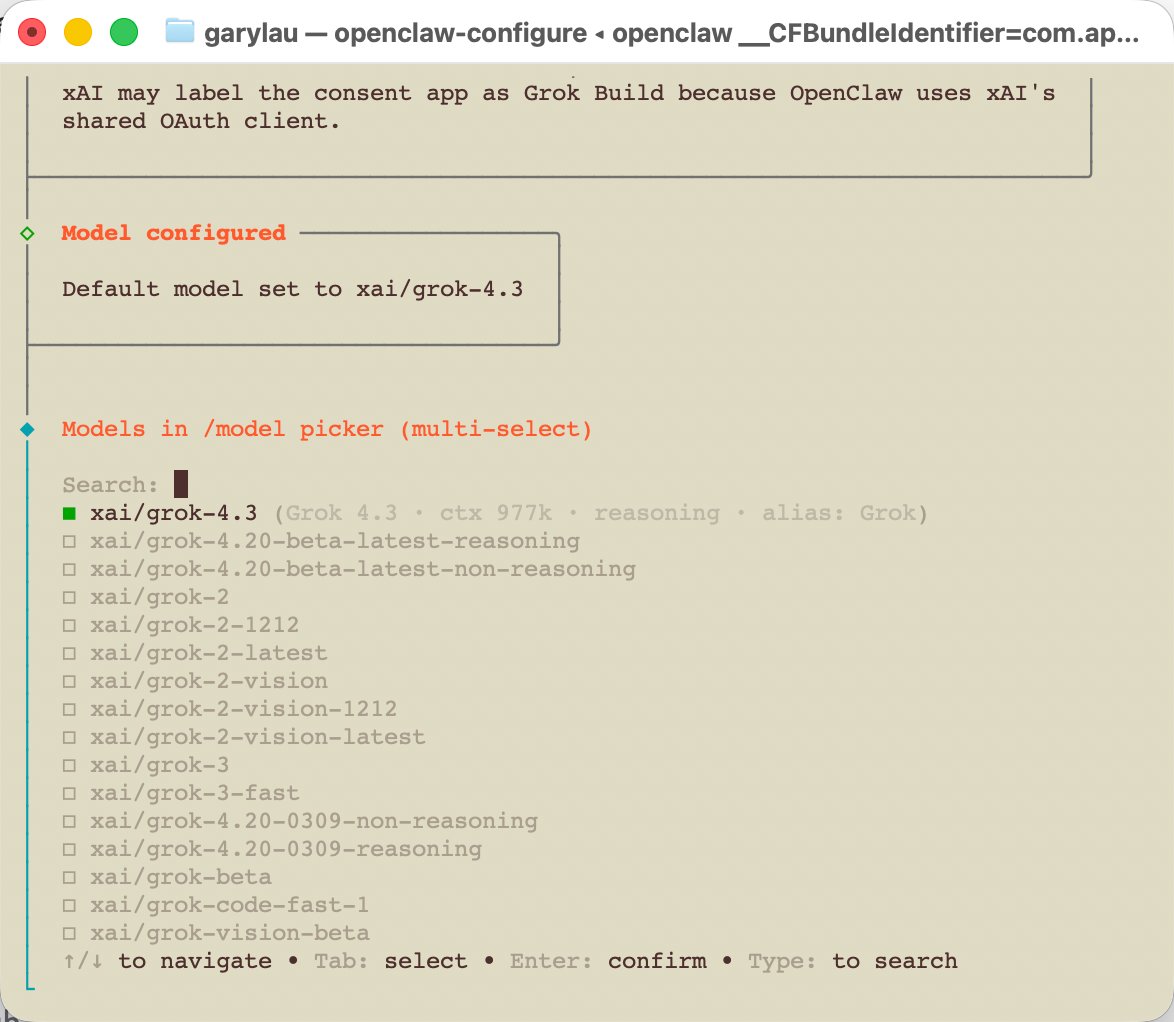
这一步对团队很重要,因为设备批准本质上是“谁可以调用这个能力”的边界。不能让任何本地客户端都随便接入 Gateway。
建议记录四个字段:
- 请求设备 ID。
- 请求来源。
- 批准人。
- 批准时间。
- 对应的任务或工作流。
这样做可以避免后续出现“谁接入了模型、谁发起了调用、为什么配额被消耗”的问题。
第七步:验证 Grok 接入 OpenClaw 是否跑通
验证不要只看“命令没报错”。更可靠的验证应该包括模型状态、OAuth 账号、Gateway 状态、设备状态和一次最小调用。
一个最小验证可以是让 Agent 只返回 OK。如果命令行能返回,网页控制台也能跑,说明基本链路已经打通。
但对团队来说,还要多看三件事:
- 模型调用是否走的是授权账号。
- Gateway 是否有访问控制。
- 日志里能否追踪到调用时间和结果。
这三件事决定它能不能进入生产任务,而不只是个人玩具。
Grok X Search:最适合先接入的自动化场景
原文最有启发的地方,是把 Grok X Search 用在定时监控上。比如让系统每小时扫描几个账号或关键词,一旦有新动态就推送给自己。
这个场景非常适合作为第一批自动化任务,因为它不直接对外发布,也不会修改账号状态。它只读取公开信息、做摘要、筛选重点,再交给人判断。
对矩阵运营来说,可以扩展成:
| 任务 | 输出 |
|---|---|
| 监控竞品账号 | 新动态摘要 |
| 监控行业关键词 | 热点列表 |
| 监控 KOL 发文 | 值得二创的主题 |
| 监控评论区反馈 | 用户需求线索 |
| 监控品牌词 | 舆情提醒 |
这类任务接入 数据分析 后,可以形成每日选题池、竞品报告和内容二创队列。
不建议直接自动化的部分
Grok 接入 OpenClaw 后,很多事情看起来都能交给 Agent。但团队不能把所有动作都自动化。
不建议第一时间自动化的包括:公开发帖、账号资料修改、批量私信、敏感内容判断、账号异常处理、付费动作和高频互动。
这些动作需要业务判断,也可能触发平台规则。更稳的做法是让 Agent 做检索、摘要、草稿、素材准备和任务提醒,把公开动作留给人工审核。
和云手机、指纹浏览器、矩阵系统怎么配合
Grok 接入 OpenClaw 解决的是模型能力接入问题。云手机、指纹浏览器、账号空间和矩阵系统解决的是账号环境、任务执行和审核协作问题。
在一个完整链路里,可以这样分工:
| 层级 | 作用 |
|---|---|
| Grok / xAI | 搜索、摘要、生成、推理 |
| OpenClaw / Gateway | 模型接入和工具调用 |
| 任务系统 | 定时、分配、重试、记录 |
| 云手机 / 浏览器环境 | 账号检查和最终人工确认 |
| 审核节点 | 决定是否发布或执行 |
如果团队已经在做 多账号管理,Grok 能力应该进入账号任务流,而不是单独漂在某个开发者电脑上。
常见问题
Grok 接入 OpenClaw 后就不用 API 了吗?
它可以利用 X Premium 账号授权和订阅配额,但具体能力、额度和限制仍以 xAI / X 实际规则为准。团队不要把它当成无限资源。
是否适合直接用来发内容?
不建议第一步就直接公开发布。更适合先做搜索、摘要、草稿、素材生成和监控提醒。
为什么要启动 Gateway?
Gateway 让本地模型能力可以被 CLI、Agent 或工作流调用,同时也提供统一入口,方便配置 Token、设备批准和日志记录。
X Search 有什么实际价值?
它适合做热点监控、竞品跟踪、KOL 动态扫描和二创选题收集。相比人工刷信息流,定时任务更稳定。
团队版最容易忽略什么?
最容易忽略权限和审计。谁授权、谁调用、谁审核、谁消耗配额,都应该有记录。
可以接入矩阵运营流程吗?
可以。建议先接入低风险任务,比如搜索、摘要、选题和草稿,再逐步接入账号检查和内容审核。
失败时应该先查什么?
先查 Node/CLI,再查 OAuth 授权,再查 Gateway 状态、Token、设备批准、模型状态和日志。
结论
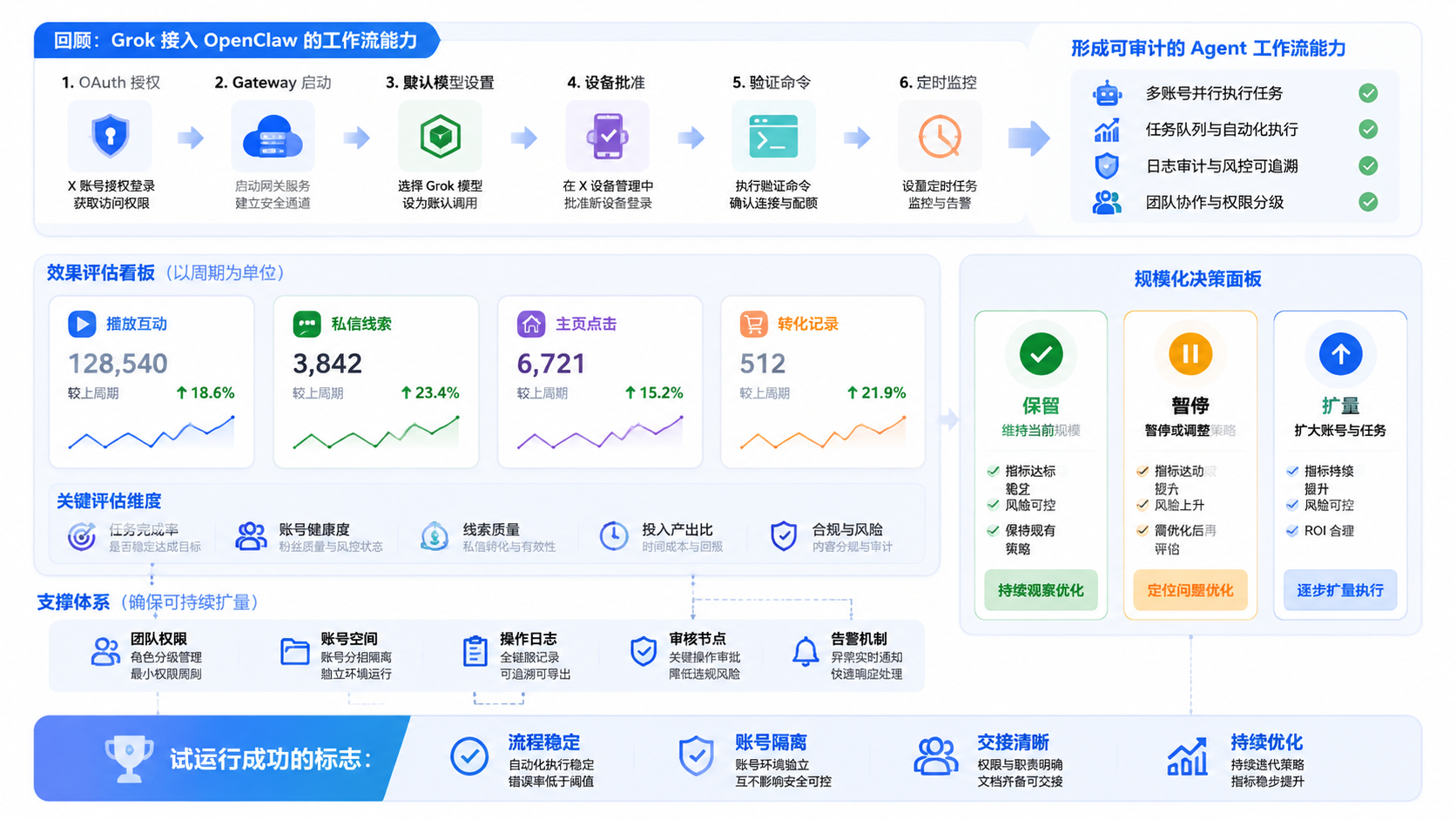
Grok 接入 OpenClaw 的完整流程,本质上是把个人订阅里的 AI 能力,改造成 Agent 可以调用的工作流能力。它的重点不是“白嫖”,而是把授权、模型、Gateway、设备、验证和任务记录串起来。
对个人来说,这能减少网页切换和复制粘贴。对团队来说,它的价值在于把 Grok Search、Grok Image 和模型能力接进任务系统,用于监控、选题、草稿和复盘。
真正适合长期运营的做法,是先跑通低风险场景,再接入账号空间、审核节点和矩阵任务。这样 Grok 才不是一个临时工具,而是可以进入团队流程的 AI 能力层。

